ChatGPT核心技术 - transformer算法¶
0 ChatGPT能做什么¶
1)ChatGPT可以回答关于各种话题的问题,例如历史、科学、文化等。它可以提供相关的信息和细节,并且能够根据上下文作出适当的回应。
2)ChatGPT可以参与自然对话,即能够与人类进行多轮交流,并作出相应的回应。它可以通过文本或语音与人类交流,并理解他们的意图,从而使对话更加流畅自然。
3)ChatGPT可以提供建议和帮助,例如在人类面临某些问题或困难时,它可以提供可行的解决方案。它可以理解人类的需求,并根据他们的问题提供适当的帮助。
4)ChatGPT可以作为学习工具,即人类可以通过与它交流来提高他们的语言能力和知识水平。它可以提供丰富的信息和知识,并且能够持续不断地学习和更新,从而为人类提供更多的学习机会。
5)ChatGPT可以作为客服或人工智能助手使用,即能够与人类进行交流,并帮助他们解决问题。它可以用于提供客户服务或帮助人们完成日常任务,从而提高工作效率和满意度。
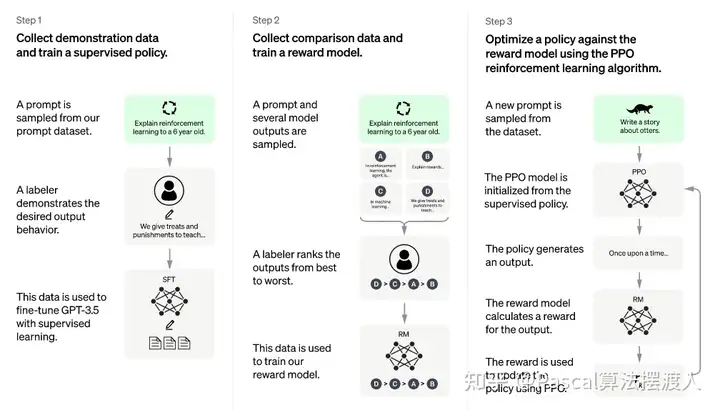
ChatGPT来自于一个名为transformer的算法,它来源于2017年的一篇科研论文《Attention is all your need》。
1 遇到问题¶
定义:机器翻译,将一种语言翻译成另一种语言。 
例如:法英翻译
输入:(法语)Je suis étudiant
输出:(英语)I am a student
备注: 我是一名学生(中文)。在法语语法中,étudiant(学生(阳性))前面是不用阳性不定冠词 un,但是在翻译成英语的时候student前面就需要有不定冠词 a 。
2 前情提要¶
1)卷积神经网络CNN¶
神经网络是一种非常有效的模型,可用于分析图像、视频、音频和文本等复杂数据类型。但是有不同类型的神经网络针对不同类型的数据进行了优化。例如,为了分析图像,我们通常会使用卷积神经网络或“CNN”。它们模糊地模仿了人脑处理视觉信息的方式。 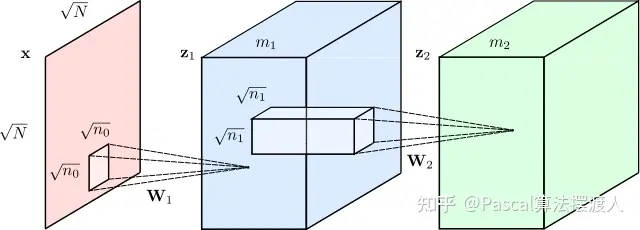
自 2012 年左右以来,我们在使用 CNN 解决视觉问题方面取得了相当大的成功,例如识别照片中的对象、识别人脸和阅读手写数字。但长期以来,语言任务(翻译、文本摘要、文本生成、命名实体识别等)都没有比这更好的了。
2)循环神经网络RNN¶
在 2017 年推出 Transformers 之前,我们使用深度学习来理解文本的方式是使用一种称为循环神经网络或 RNN 的模型,它看起来像这样: 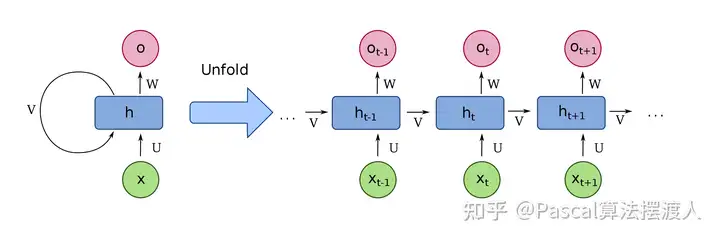
假设您想将一个句子从英语翻译成法语。循环神经网络会将英语句子作为输入,一次处理一个单词,然后依次吐出对应的法语单词。这里的关键词是“顺序”。在语言中,单词的顺序很重要,你不能随意乱序。
任何要理解语言的模型都必须捕捉词序,而循环神经网络通过按顺序一次处理一个词来做到这一点。
但是 RNN 有问题:
1)他们很难处理大量文本序列,例如长段落或文章。 2)到段落结尾时,他们会忘记开头发生的事情。例如,基于 RNN 的翻译模型可能难以记住长段落主题的性别。 3)RNN 很难训练。众所周知,它们很容易受到所谓的消失/爆炸梯度问题的影响(有时你只需要重新开始训练并祈祷)。 4)因为它们按顺序处理单词,RNN 很难并行化。 这意味着您不能仅仅通过向它们投放更多 GPU 来加快训练速度,这反过来又意味着您无法在所有那么多数据上训练它们。
3 解决方案¶
这就是Transformer改变一切的地方。它们由谷歌和多伦多大学的研究人员于 2017 年开发,最初旨在进行翻译。但与循环神经网络不同,Transformer 可以非常高效地并行化。这意味着,使用合适的硬件,你可以训练一些非常大的模型。
多大?
很大很大。
GPT-3 是一种特别令人印象深刻的文本生成模型,它的书写能力几乎与人类一样好,它在大约45 TB的文本数据上进行了训练,包括几乎所有的公共网络。
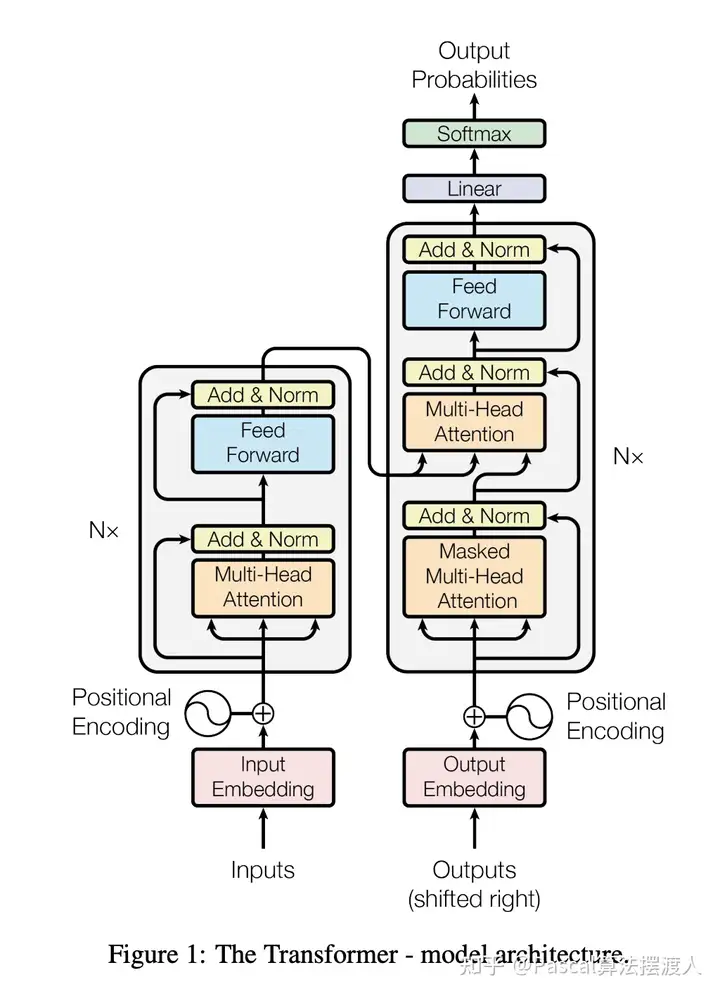
Transformer模型架构是由编码器( Encoder )与解码器( Decoder )组成。
1)每个编码器(左边)由 1个位置编码层(Positional Encoding)与N(= 6)个编码层( Encoder Layer )组成。
2)每个解码器(右边)由1个位置编码层与N个解码层( Decoder Layer )以及1个以全连接层和Sotfmax为激活函数组成。
1)编码部分¶
0)输入编码(Input Embedding)¶
1)位置编码(Positional Encodings)¶
让我们从第一个开始,位置编码。假设我们正在尝试将文本从英语翻译成法语。请记住,RNN 是一种旧的翻译方式,它通过按顺序处理单词来理解单词顺序。但这也是使它们难以并行化的原因。
Transformer通过一种称为位置编码的创新技术绕过了这一障碍。这个想法是获取输入序列中的所有单词——在本例中是一个英语句子——然后为每个单词附加一个它的顺序。因此,您为网络提供如下序列:
[("Dale", 1), ("says", 2), ("hello", 3), ("world", 4)]
从概念上讲,您可以将此视为将理解词序的负担从神经网络的结构转移到数据本身。
起初,在对任何数据进行训练之前,Transformer 并不知道如何解释这些位置编码。但随着模型看到越来越多的句子示例及其编码,它会学习如何有效地使用它们。
我在这里做了一些过度简化——原作者使用正弦函数来进行位置编码,而不是简单的整数 1、2、3、4——但要点是一样的。将词序存储为数据而非结构,您的神经网络将变得更易于训练。

2)注意力(Attention)¶
早在两年前,即 2015 年,在翻译的背景下引入了注意力。
要理解它,请从原始论文中取出这个例句:
欧洲经济区协定于1992年8月签署。
现在想象一下,试图将这句话翻译成对应的法语:
L'accord sur la zone économique européenne a été signé en août 1992。
尝试翻译该句子的一种糟糕方法是遍历英语句子中的每个单词,然后尝试吐出其对应的法语,一次一个单词。出于多种原因,这种做法效果不佳,但其中一个原因是,法语翻译中的某些词被颠倒了:英语是“欧洲经济区”,但法语是“la zone économique européenne”。此外,法语是一种带有性别词的语言。形容词“économique”和“européenne”必须是阴性形式才能匹配阴性宾语“la zone”。 
具体计算公式 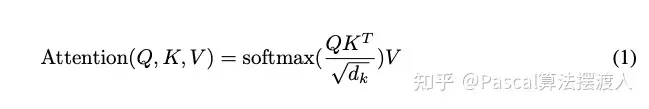
3)自注意力(Self-Attention)¶
d_model = 512
自注意力 : Q = K = V
多头注意力 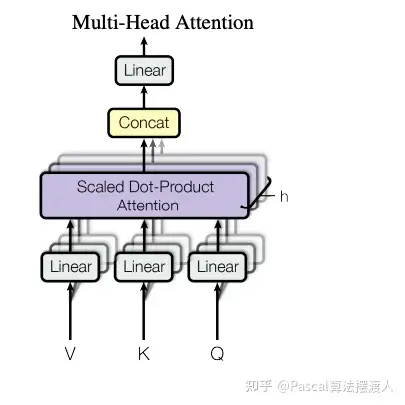
计算公式 
小结:编码部分计算流程¶
例如:翻译句子“我爱你”到“I love you”。
第一步:输入编码。首先进行向量化并吸收句子位置信息,得到一个句子的初始向量组。
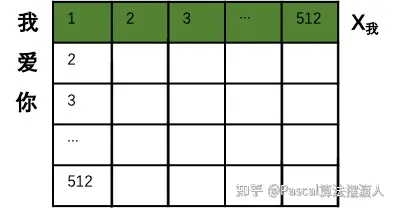
(由于样本每个句子长短不同,所以每个句子都会是一个512*512的矩阵,如果长度不够就用0来代替。这样在训练时,无论多长的句子,都可以用一个同样规模的矩阵来表示。当然512是超参,可以在训练前调整大小。)
第二步:随机初始化
用每个字的初始向量分别乘以三个随机初始的矩阵WQ,Wk,Wv分别得到三个量Qx,Kx,Vx。
下图以“我”举例。 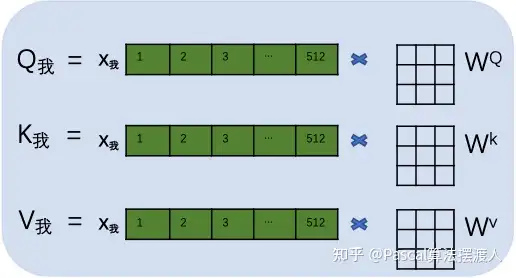
第三步:计算每个单词的attention数值
比如“我”字的attention值就是用“我”字的Q我分别乘以句子中其他单词的K值,两个矩阵相乘的数学含义就是衡量两个矩阵的相似度。然后通过一个SoftMax转换(大家不用担心如何计算),计算出它跟每个单词的权重,这个权重比例所有加在一起要等于1。再用每个权重乘以相对应的V值。所有乘积相加得到这个Attention值。 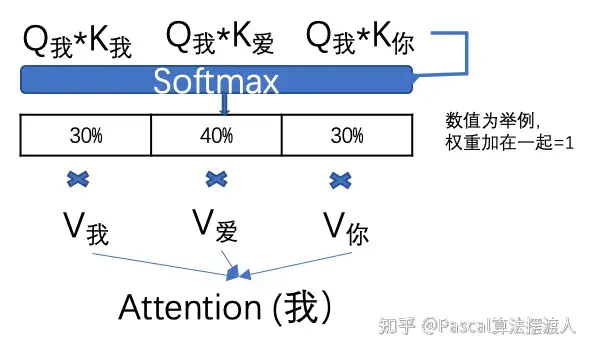
这个attention数值就是除了“我”字自有信息和位置信息以外,成功的得到了这个句子中每个单词的相关度信息。
大家可以发现,在所有注意力系数的计算中其实只有每个字的初始矩阵WQ,Wk,Wv是未知数(这三个矩阵是所有文字共享的)。 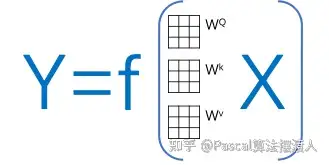
那么我们可以把这个transformer简化成一个关于输入,输出和这个W矩阵的方程:其中X是输入文字信息,Y是翻译信息。
Transformer¶
CV¶
Pascal:[CV-图像分类]ViT模型----An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale
Pascal:ViT - Vision Transformer 应用展示
Pascal:[CV - Image Classification]图像分类 MoblieViT模型 - 混合CNN和Transformer的轻量化网络
Pascal:[CV]ViT的复仇 - DeiT III: Revenge of the ViT
Pascal:[CV-Backbone]MAE模型 - Masked Autoencoders Are Scalable Vision Learners
Pascal:[CV - Backbone] Swin Transformer模型
NLP¶
Pascal:Transformer模型系列(1)
Pascal:Transformer模型(2)
Pascal:Transformer模型(3)- Input Embedding
Pascal:Transformer模型(4)- Positional Encoding
Pascal:计算机视觉领域(CV):Transformer机制
Pascal:[NLP - Backbone] BERT模型(上) - 开启NLP新篇章预训练模型
Pascal:[NLP - Backbone] BERT模型(中) - 开启NLP新篇章预训练模型
Pascal:[NLP - Backbone] BERT模型(下) - 开启NLP任务新篇章预训练模型
Pascal:[NLP - Backbone] BERT模型 - 开启NLP新篇章预训练模型
Pascal:[NLP]BERT- Bidirectional Encoder Representations from Transformers