Transformer:让ChatGPT站在肩膀上的巨人?¶
编者按:ChatGPT以近乎狂热之势席卷了全网。在沉浸于“ChatGPT潮”的同时,让我们也来深入了解一下它和基石技术 - 大模型 Transformer吧。
Dale Markowitz的这篇文章为我们深入浅出地介绍了Transformer的重要性、创新性、应用领域等。
以下是译文,Enjoy!
作者 | Dale Markowitz
编译 | 岳扬
你知听说过这句话吗?当你拥有一把锤子时,所有东西看起来都像钉子。那么,在机器学习中,我们似乎真的发现了一个神奇的锤子,对于它来说,所有的东西都是钉子,它们被称为Transformers。
Transformers是可以被设计用来翻译文本、写诗和文章的模型,甚至可以生成计算机代码。很多备受瞩目的模型就是基于Transfomer, 如风靡全网的ChatGPT, AlphaFold 2(这个模型可以根据蛋白质的基因序列预测其结构),以及其他强大的自然语言处理(NLP)模型,如GPT-3、BERT、T5、Switch、Meena等等。
如果你想在机器学习,特别是NLP方面跟上时代的步伐,那么至少要对Transformers有一定的了解。因此,在这篇文章中,我们将讨论Transformers是什么,它们如何工作,以及它们为什么如此有影响力。
Transformers是神经网络架构的一种类型。简而言之,神经网络是一种非常有效的模型类型,用于分析图像、视频、音频和文本等复杂数据类型。但有不同类型的神经网络为不同类型的数据进行优化。例如,对于分析图像,我们通常会使用卷积神经网络[1]或 “CNNs”。其实可以说它们模仿了人脑处理视觉信息的方式。
而自2012年[2]左右开始,我们在用CNN解决视觉问题方面已经相当成功,比如识别照片中的物体、识别人脸和手写数字。但在很长一段时间里,没有任何类似的好方法存在于语言任务(翻译、文本总结、文本生成、命名实体识别等)的处理中。这是不幸的,因为语言是我们人类交流的主要方式。
在2017年出现Transformers之前,我们使用深度学习来理解文本的方式是使用一种叫做循环神经网络或RNN的模型:
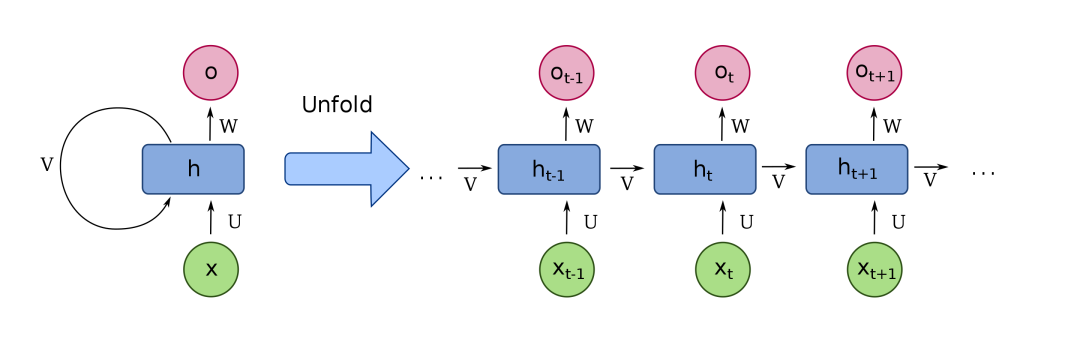
比方说,你想把一个英语句子翻译成法语。RNN会把英语句子作为输入,一次处理一个词,然后按顺序输出它们的法语对应词。这里的关键是“按顺序”。在语言中,单词的顺序很重要,不能随便更改。
"Jane went looking for trouble."
上面这句话与下面下面这句话的意思完全不同。
"Trouble went looking for Jane."
因此,任何要理解语言的模型都必须捕捉到单词的顺序,而递归神经网络(recurrent neural networks)通过一次处理一个单词的方法来做到这一点。
但是,RNN也存在很多问题。首先,它们在处理大型文本序列时很吃力,比如长段文本或文章。当到了一个段落的结尾时,它们会忘记开头发生了什么。例如,一个基于RNN的翻译模型可能难以记住一个长段落的主题。
更糟的是,RNNs很难训练。它们很容易受到所谓的梯度消失/膨胀问题[3]影响(有时你只需重新开始训练,然后祈祷)。更麻烦的是,由于它们是按顺序处理单词,RNNs很难达到并行化。这意味着你不能通过使用更多的GPU来加快训练,这反过来意味着你不能在所有的数据上训练它们。
01 进入Transformers的世界¶
Transformers是由谷歌和多伦多大学的研究人员在2017年开发的,最初是为了做翻译。但与递归神经网络(RNN)不同,Transformers可以非常有效地进行并行化操作。这意味着,如果有合适的硬件条件,你可以训练一些真正的大模型。
多大的大模型?
非常大。
如果要说一件关于 Transformers 的事情,那应该会是:将一个具有良好扩展性的模型与一个巨大的数据集相结合,其结果可能会让你大吃一惊。
02 Transformers是如何工作的?¶
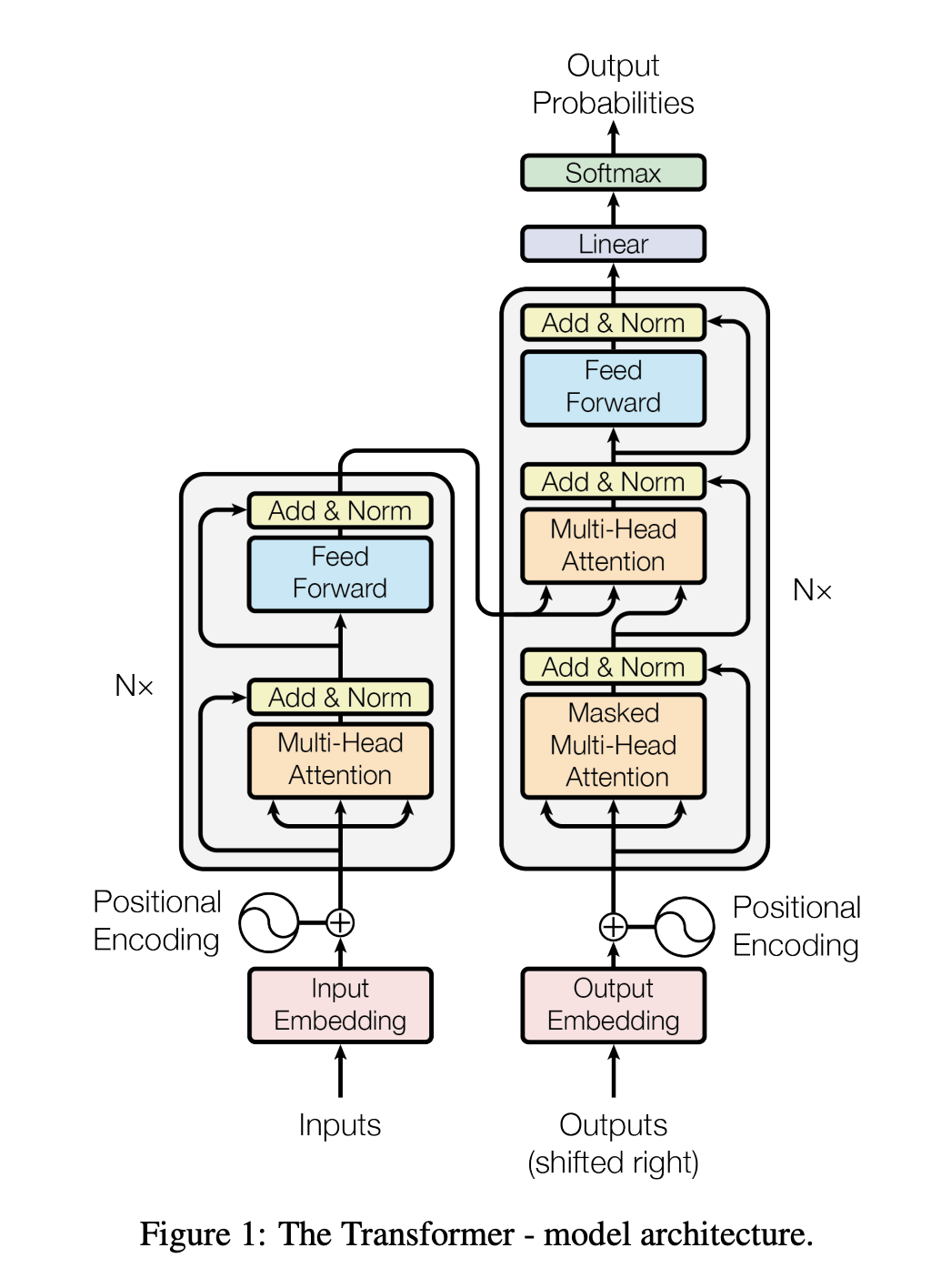
虽然原始论文[4]的图表有点吓人,但Transformer背后的创新可以归结为三个主要概念。
-
Positional Encodings位置编码
-
Attention注意力
-
Self-Attention自注意力
2.1 Positional Encodings位置编码¶
让我们从第一个——位置编码开始介绍。比方说,我们正试图将文本从英语翻译成法语。RNNs,即用AI进行文本翻译的老方法,通过按顺序处理单词来理解词序。但这也是使它们难以并行化的原因。
Transformers通过一种叫做位置编码的创新方法绕过了这个障碍。这个想法是把你的输入序列中的所有单词(在这个例子中是一个英语句子)用它的顺序给每个单词附加一个数字。因此,要给你的网络提供一个序列,如:
[("Dale", 1), ("says", 2), ("hello", 3), ("world", 4)]
从概念上讲,你可以认为这是把理解词序的负担从神经网络的结构转移到数据本身。
起初,在Transformers对任何数据进行训练之前,它不知道如何解释这些位置编码。但随着模型看到越来越多的句子及其编码的例子,它学会了如何有效地使用它们。
我在这里做了许多简化——原作者是使用正弦函数来进行位置编码,而不是简单的整数1、2、3、4,但重点是一样的。将词序存储为数据,而不是结构,这样神经网络就变得更容易训练了。
2.2 Positional Encodings位置编码¶
Transformers的下一个重要部分叫做注意力。
注意力是一种神经网络结构,如果你在学习机器学习,你就能够经常听到。事实上,2017年介绍Transformers的论文的标题并不叫《We Present You the Transformer》。相反,它被称为 “Attention is All You Need”。
注意力[5]是在论文的两年前,即2015年,在文本翻译的背景下引入的。为了理解它,请看原始论文中的这个例句。
The agreement on the European Economic Area was signed in August 1992.
现在想一下,将这句话翻译成法语的相应内容:
L’accord sur la zone économique européenne a été signé en août 1992.
翻译这句话的一个坏方法是:通过英语句子中的每个单词找到其法语的对应词,一次一个单词。这样做效果并不好,原因有几个。首先,法语翻译中的一些词被颠倒了:英语是 “European Economic Area”,而法语是 “la zone économique européenne”。另外,法语是一种带有性别色彩的语言。形容词 “économique” 和 “européenne” 必须采用阴性形式,以配合阴性对象 “la zone”。
注意力(Attention)是一种机制,允许文本模型在决定如何翻译输出句子中的单词时 “查看” 原句中的每一个单词。这里有该过程的可视化图片,来自那篇关于注意力的论文。

这是一种热力图,显示了模型在输出法语句子中的每个词时 “关注” 的地方。正如我们想要的那样,当模型输出 “européenne” 这个词时,它重点关注了 “European”和 “Economic”这两个输入词。
那么,模型是如何知道它在每个步骤中应该 “关注”哪些词的呢?这是从训练数据中学习到的东西。通过看到数以千计的法语和英语句子的例子,该模型学会了哪些类型的词是相互依赖的。它学会了如何遵循词性别、复数和其他语法规则。
自2015年出现以来,注意力机制一直是自然语言处理的一个非常有用的工具,但在其原始形式下,它是与递归神经网络一起使用的。所以,2017年Transformers论文的创新之处在于,在某些部分完全抛弃了RNN。这就是为什么2017年的论文被称为 “Attention is all you need”。
2.3 Self-Attention自注意力¶
Transformers的最后一部分(也许是最有影响的一部分)是对注意力的一种改变,称为 “自注意力”。
我们刚才谈到的那种注意力有助于在英语和法语句子中对齐单词,这对翻译很重要。但是,如果你不是要翻译单词,而是要建立一个能够理解语言中潜在意义和模式的模型——一种可以用来完成任何数量的语言任务的模型,那该怎么办呢?
一般来说,使神经网络变得强大、令人激动和酷的原因是它们通常会自动建立它们所训练的数据的有意义的内部表示。例如,当你检查视觉神经网络的各层时,你会发现有几组神经元可以“识别”边缘、形状,甚至像眼睛和嘴巴这样的高级结构。一个根据文本数据训练的模型可能会自动学习语篇、语法规则,以及单词是否是同义词。
一个神经网络学习的语言内部表征越好,它在任何语言任务中的表现就越好。而事实证明,如果把注意力放在输入文本本身上,它可以是一个非常有效的方法。
以这两句话为例。
“Server, can I have the check?”
“Looks like I just crashed the server.”
server这个词在这里有两种截然不同的意思,我们人类可以通过观察周围的词来轻易地将其区分开来。自注意力允许神经网络在它周围的词的背景下理解一个词。
因此,当一个模型处理第一句中的 “server”一词时,它可能会注意到“check”一词。
在第二句中,该模型可能会注意到 “crashed”这个词,以确定“server”是指一台机器。
自注意力有助于神经网络区分单词、进行语篇标记、实体解析、学习语义角色以及更多[6]。
如果你想了解更深入的技术解释,我强烈建议你看看Jay Alammar的博文:http://jalammar.github.io/illustrated-transformer/。
03 Transformers能做什么?¶
BERT是最受欢迎的基于Transformers的模型之一,是 “Bidirectional Encoder Representations from Transformers” 的简称。它是由谷歌的研究人员在2018年推出的,并很快进入了几乎所有的NLP项目(包括谷歌搜索[7])。
BERT指的不仅仅是一种模型架构,而是一个经过训练的模型本身,你可以在这里(https://github.com/google-research/bert)免费下载和使用它。它是由谷歌的研究人员在一个巨大的文本语料库上训练出来的,并且已经成为NLP的瑞士军刀,可以扩展解决一堆不同的任务,比如。
-
文本总结
-
问题回答
-
文本分类
-
命名实体解析
-
文本相似性
-
攻击性/冒犯性语言检测
-
了解用户查询内容
-
...
BERT证明,你可以在无标签的数据上进行训练来创建比较好的语言模型,比如从维基百科和Reddit收集的文本,然后这些大型 “基础”模型可以用特定领域的数据来适应许多不同的使用情况。
由OpenAI创建的模型GPT-3[8],其生成文本的能力有目共睹。(编者:最近爆火的ChatGPT也有Transformer的功劳!)。谷歌研究院推出的Meena[9]是一款基于Transformers的聊天机器人(akhem,“conversational agent”),可以就几乎任何话题进行对话(本文作者曾经花了20分钟与Meena争论什么是人类)。
Transformers也在NLP之外掀起了波澜,它可以谱写音乐,通过文本描述中生成图像,并预测蛋白质结构。
———————————————— 版权声明:本文为CSDN博主「Baihai IDP」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/Baihai_IDP/article/details/128375311