如何评价 OpenAI 的超级对话模型 ChatGPT ?¶
作者:曹越 链接:https://www.zhihu.com/question/570189639/answer/2787763735 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
先从Jason Wei的这条推开始。
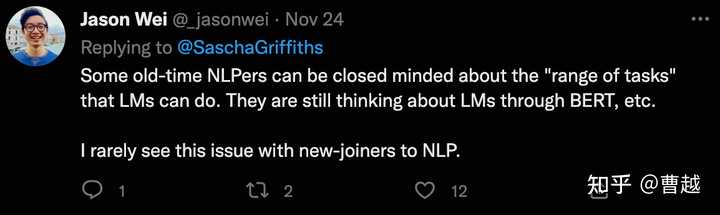
现如今还有很多old-time NLPers停留在BERT时代,思考BERT训练的LM能做的一些任务,而他自己很少看到新加入的NLPers有这个问题。从我个人的理解,他这里说的new-joiners,大概指的是在GPT3出现之后加入到NLP领域并进行探索的人,当然包括他自己。
而从这个角度,国内的情况更为夸张。首先,GPT3的API需要收费,并且国内IP是没法直接访问的,我个人也和很多国内NLPers进行了交流,大家对于GPT3甚至后GPT3时代语言模型的进展了解寥寥,大家对于GPT3、GPT3.5(davincci001/002)有什么样的能力了解都这么少,更遑论训练出这样的模型了。这确确实实让我强烈的感受到了"卡脖子"的感觉。
近期看到很多人不管是在朋友圈还是知乎回答,一遍又一遍的验证了这条推特的说法。我甚至还看到有人觉得训练出这样的模型“不算太难”,据我了解,在GLM130B出来之前,国内甚至没有一个能对标2020年6月OpenAI发布的GPT3的模型,更别说他们后续远远更强大的GPT3.5(davincci001/002)和近期新闻满天飞的GPT4了,让我自己真实的感觉到信息茧房的可怕。但ChatGPT的火爆让我觉得很幸运,至少在这个时刻,更多的人可以看到他们模型的能力,也就有更多的人可以看到差距,激发更多人去思考。
后面说一点我自己作为视觉领域的研究者(外行),对于GPT3时代的理解,以及近一两年的一些思考和思维变化。
近期在写paper时重读GPT-3,才发现自己之前一直都没有真正理解in-context learning的含义,而只是表面的认为其就是不fine-tune而冻住主要的模型参数,也从而大大低估了in-context learning的能力。在NLP领域,或许这个in-context的能力是auto-regressive LLM scale到比较大之后的emergent property,但视觉任务因为不同任务输出空间差异很大,所以如何在视觉领域进行in-context learning一直都是个悬而未决的问题,也有很多工作试图将不同任务统一到一个输出空间(pix2seq、unified-io、uvim等),但都未窥visual in-context learning的门径:即需要将任务输入和输出一起concat起来输入到模型中,而非传统的图像作为输入、任务输出作为模型输出。
在理解了visual in-context learning之后,我才某种程度上对于我们落后openai的代际有了一定的认知(嘲笑自己在2022年11月才进一步读明白OpenAI在2020年6月发布的文章)。在这之后,又再次拜读了后GPT-3时代的一系列文章,webgpt、instructGPT、alignment research等,才发现在GPT-3之后,他们一直在探索的其实就是新的loss signal(驱动模型训练的信息),这可能也是因为他们先意识到auto-regressive LLM这种预测式的输出的局限性,比如对于一些之前文章没出现过的问题难以给出回答,例如WebGPT中长江还是尼罗河哪个更长的例子,哈利波特和指环王哪个字数更多等,这些问题都难以从LM这种任务中直接学到。而他们好像探索出了一条路径,基于GPT3对于语言的理解作为预训练模型,再使用强化学习去校正模型来拟合人对于很多知识的理解和语言的生成。(非常非常感谢 @Trinkle在回答中帮我个人验证了这个猜测,RLHF)
在我自己理解了这个LLM+RL的loop之后,我自己深切的感受到好像真的找到了一条通往AGI的路径了。就着这个问题和很多人交流过,让我印象最深的是和黄铁军老师交流时他给出了一个例子:有研究表明,尽管盲人看不见,并且大多数是通过语言进行交流和反馈的,但他们和视力正常的人对颜色这种抽象视觉概念有着相似的理解,这个对色彩的理解是在盲人想象中的世界里的。LM+RL甚至也能帮助人类理解视觉,当然对于在LM里加入视觉信号,对OpenAI而言或许并不是一件难事,Flamingo已经给出了一个非常强的solution。
而在ChatGPT中,看到一个有点相似而又令人无比惊艳的例子,Building A Virtual Machine inside ChatGPT,让ChatGPT去想象自己是一个Linux Terminal,并且进行交互,下面是这个blog给出的几个例子,大家可以自行感受。
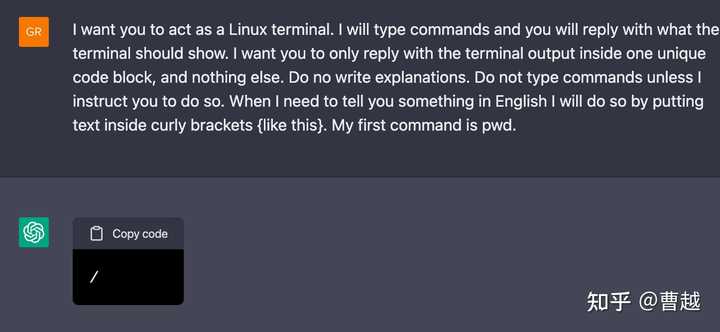

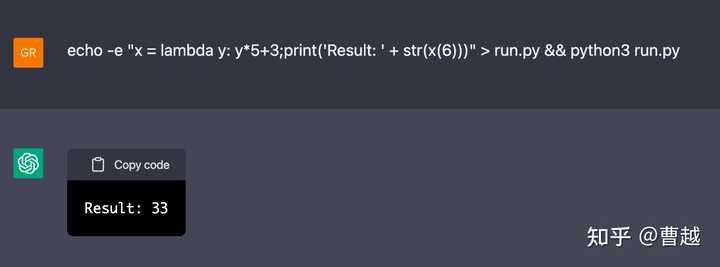

ChatGPT的出现真的是很幸运,它打破了国内国外的信息壁垒、打破不同领域的壁垒,让更多人看到了这样的工作。
我真的希望各个领域的研究者,特别是相对比较senior的研究者们,能够去仔细阅读OpenAI的一系列文章,真的花些时间去理解现在世界最前沿的研究进展到了什么阶段,多看一些墙内墙外的examples,甚至自己去试一试,努力去理解后GPT3时代语言模型的能力,这真的比再在自己的领域中固步自封重要太多了。
期待国内也早日能有像OpenAI一样的公司出现,产出GPT3级别的工作。