从零实现ChatGPT——RLHF技术笔记¶
最近OpenAI推出的问答模型ChatGPT掀起了新的AI热潮,从技术问答到玩场景play,从代写论文到聊天解闷,有趣到让人产生图灵测试已经不在话下的感觉。看了很多对话梗图以后惊艳于技术之余,也产生了不少疑问,似乎和一般的语言模型能做到的事相去甚远,看了一些RLHF相关的材料惊觉自己的认知还停留于BERT时代。
本文会按个人理解分析Huggingface的一篇博客Illustrating Reinforcement Learning from Human Feedback (RLHF)。我觉得原文写的很好,建议看原文,为了学习(蹭热度)搬运过来了。抛砖引玉,欢迎讨论。
BTW这个标题不是我起的,来源于Hug的直播(北京时间12.14凌晨,有时间可以看看):
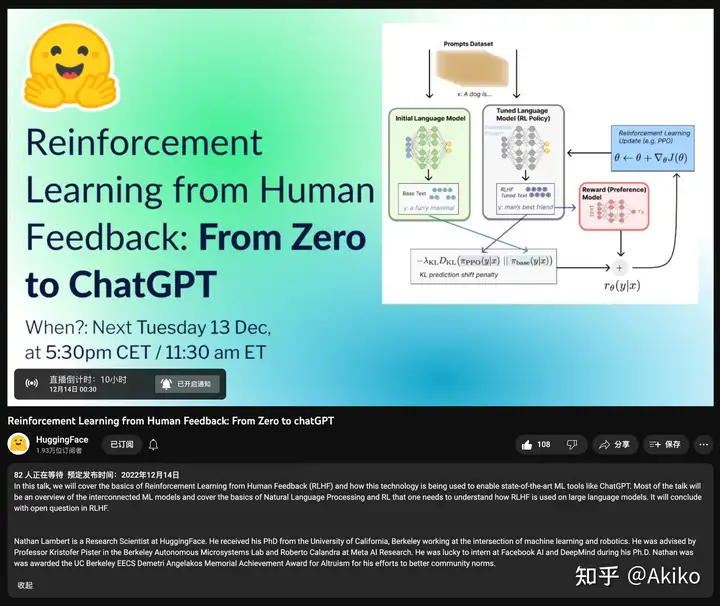
RLHF整体框架¶
字面上说,RLHF就是基于人类反馈(Human Feedback)对语言模型进行强化学习(Reinforcement Learning),和一般的fine-tune过程乃至prompt tuning自然也不同。
属于是在玩一种很新的东西……所以下面这些都还只是探索,并不是固定的流程。
根据OpenAI的思路,RLHF分为三步:
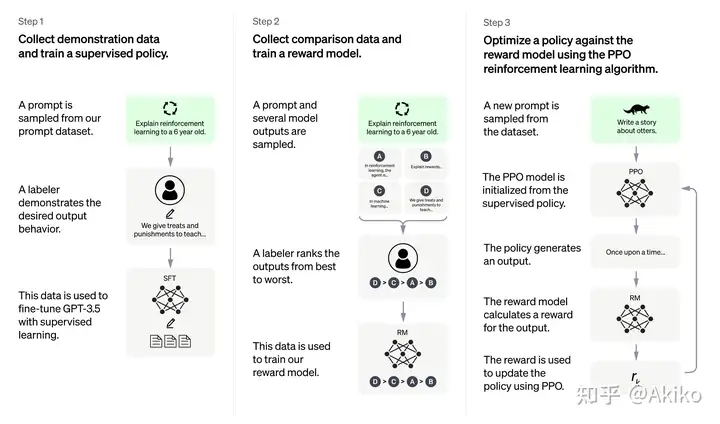
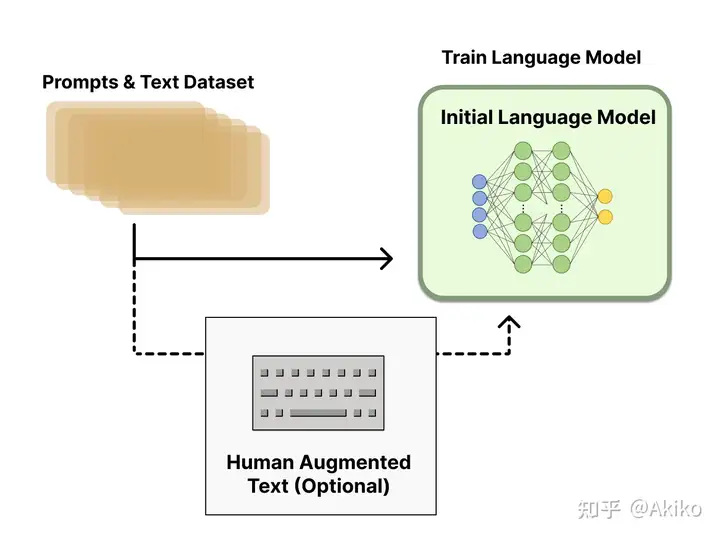
1,花钱招人给问题(prompt)写回答(demonstration),然后finetune一个GPT3。这一步大家都懂,就不用说了。这一步可以多训几个版本,第二步会用到。
2,用多个模型(可以是初始模型、finetune模型和人工等等)给出问题的多个回答,然后人工给这些问答对按一些标准(可读性、无害、正确性blabla)进行排序,训练一个奖励模型/偏好模型来打分(reward model)。
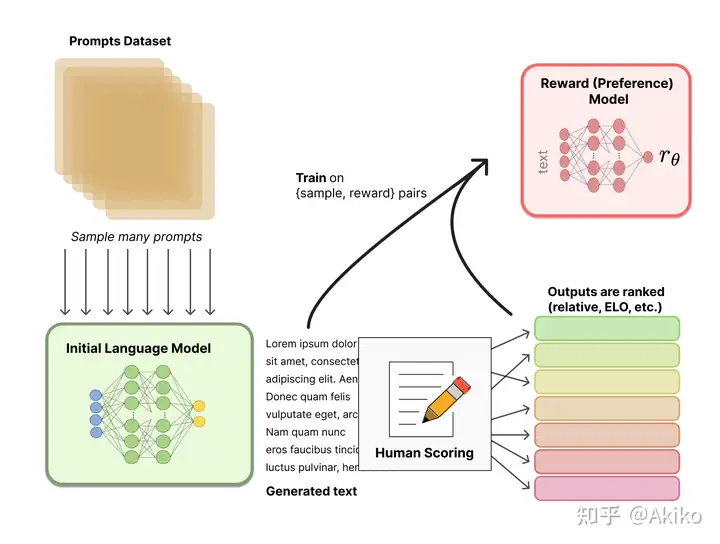
第二步
到这里会产生一些问题。
问题一,为什么不人工直接打分?因为打分是主观的需要归一化,而排序一般大家会有共同的结论:对同一个问题,A和B哪个回答更好。
问题二,有了一组一组的偏序(A>B, A>C, C>B)怎么得到每个回答的奖励分数?这一步在Hug的博客里用了Elo排名系统,打网游排位赛、看足球篮球比赛的可能都知道:
https://link.zhihu.com/?target=https%3A//bbs.gameres.com/thread_228018_1_1.html
把每个偏序当作比赛,把奖励分数看作排位分,完美契合匹配排位赛有没有!当然这里我们是用Elo得到一个完整排序后,经过归一化得到了奖励分数。
问题三,这个RM用什么模型?只要用Elo系统打分后归一化,然后直接上个LM做回归就行,可以从零训练也可以用老LM做finetune。这里有个有趣的事情在于,做问答和做评分都需要输入所有的文本,实际上两个模型的容量(或者说理解能力)应该是差不多的,而现有的RLHF模型都使用了两个不同大小的模型。
问题四,有没有其他方式训练打分的模型?这里我看到张俊林老师指出对偏序直接用pairwise learning to rank做打分,大概更符合常规的思路,当然具体效果如何就需要看实践了:
https://zhuanlan.zhihu.com/p/589533490
好了,现在我们有一个RM给每个输入的问答对打分,这样就得到了强化学习中的reward。于是我们走到最后也是最关键的一步:
3,用强化学习训练上面那个finetune后的GPT3模型。用强化学习做LM训练的一种思路是用Policy Gradient做,这一块OpenAI用的是他们在17年提出的PPO算法,即Proximal Policy Optimization。
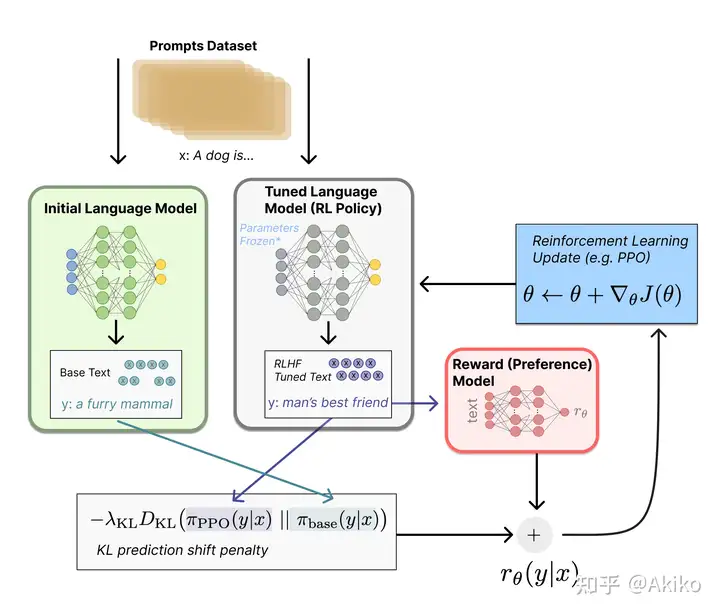
第三步
首先定义强化学习的场景:

这里原文的action space是词表大小,个人认为应该是输出序列的空间,即全词表大小 x 序列长度的空间。 补充评论区意见:按理说应该 action space 是每个 token,然后 reward 在句子不完整的时候是 0,句子完整的时候是 reward model 给出来的一个值。就像围棋吧,盘中没有 reward,终局才有。
然后根据OpenAI在2017年提出的PPO算法进行RL更新。训练中这里可以加一些辅助的预训练梯度,比如InstructGPT就用了,这块之后读了论文再补充。
OK,这样从零训练ChatGPT的三个步骤就完成了,是不是觉得很简单!但是俗话说魔鬼藏在细节里,具体的实现和工程技巧才是重头戏。
一个问题是训练这样的模型需要多少数据和人力标注?Hug给出的回答是,因为人工写回答要求质量高所以不能用众包。不过对RM模型的训练,需要的标注不多:
Thankfully, the scale of data used in training the reward model for most applications of RLHF (~50k labeled preference samples) is not as expensive. However, it is still a higher cost than academic labs would likely be able to afford.
考虑到RL有可能改变NLP整体的训练范式,我认为还是有必要学习一个。所以下面就讲讲RL,主要讲这里的PPO是怎么一回事,有相关了解的可以跳过了。
RL:什么是PPO¶
这一节主要参考: https://link.zhihu.com/?target=https%3A//towardsdatascience.com/proximal-policy-optimization-ppo-explained-abed1952457b
首先我们要理解什么是策略梯度(Policy Gradient)。
以下推导过程包含很多个人理解,并不很严谨,有错误欢迎指出!
粗糙理解RL的过程就是,让智能体在一个状态S下选择动作A,然后获得收益R,然后我们希望优化选择动作的策略,使得总体收益的期望最大。因为搜索空间很大,我们利用模型的预测结果决策,同时为了不让模型陷入局部最优而按蒙特卡洛方式一定比例随机游走,在这个过程中得到每个state-action对应的reward作为新的训练样本,即所谓的探索和利用(Exploration and Exploitation)过程。

为什么要写成期望呢?因为实际计算我们用多次采样的平均值就能作为期望的近似值。


相关资料¶
首先是相关论文。
关于近期的相关论文,直接看原博客下面的链接就行,我这里截个图作memo:

其次是代码。
OpenAI在2019年就做了一个基于tf做RLHF的项目:https://github.com/openai/lm-human-preferences
用torch的也有不少,这些都是Hug的博客里推的项目:
- GitHub - lvwerra/trl: Train transformer language models with reinforcement learning.
- https://github.com/CarperAI/trlx
- https://github.com/allenai/RL4LMs
建议观望一下,因为:
Both TRLX and RL4LMs are under heavy further development, so expect more features beyond these soon. 毕竟大家都不希望好好的用到一半API都改完了吧(说的就是你tf),当然huggingface自己也好不到哪里去。
此外还有一些相关的项目,比如chatgpt的google插件:https://github.com/wong2/chat-gpt-google-extension
另外,我个人实践用过的chatgpt API(非官方)里面,能用的有:GitHub - acheong08/ChatGPT: Lightweight package for interacting with ChatGPT's API by OpenAI. Uses reverse engineered official API.
不过貌似OpenAI加了cloudflare保护之后这些工具都失效了,再观察一下吧。
杂谈:Why RL?¶
看完hug的博客让我有一种“就这”的感觉。如果只是在finetune阶段引入了RL,也没法说服我们为啥ChatGPT能做到这么强的效果,只能说OpenAI大概有一些数据集构建的技术,另外也许有一些神秘的建模逻辑没有公开……这里期待和大家评论区里讨论讨论。
可以设想一种场景的比较:尝试直接用human feedback作监督信号,用第二步得到的RM模型的打分作为finetune模型的loss权重来finetune一个gpt-3,这样做和引入RL的训练效果比较如何呢?
另外一个问题在于,如果持续训练这样一个模型,依然会遭遇灾难性遗忘的问题……作为搜索引擎估计是不太行了,在张俊林老师的文章里也有一些相关的讨论,也许未来是二者相辅相成的发展模式。
关于ChatGPT在未来是不是能做成AGI,商业应用的问题,我的姿势水平有限就暂时不评价了;但是不觉得这很酷吗?作为一名理工男我觉得这太酷了,很符合我对未来生活的想象,科技并带着趣味。
(来源:知乎,侵删)