【强化学习 229】ChatGPT/InstructGPT¶
一文解读 ChatGPT 的技术细节!
原文传送门 Ouyang, Long, et al. "Training language models to follow instructions with human feedback." arXiv preprint arXiv:2203.02155 (2022).
ChatGPT 试用连接:https://chat.openai.com/chat
 挺好的,省得我自己写了。ChatGPT 和这篇 paper 里面提的 InstructGPT 使用类似的方式来训练。
挺好的,省得我自己写了。ChatGPT 和这篇 paper 里面提的 InstructGPT 使用类似的方式来训练。
一、挑战¶
语言模型规模越来越大,但是这样的模型却不能很好地贴合用户的需求,文章中把这样的问题称作 misalignment。

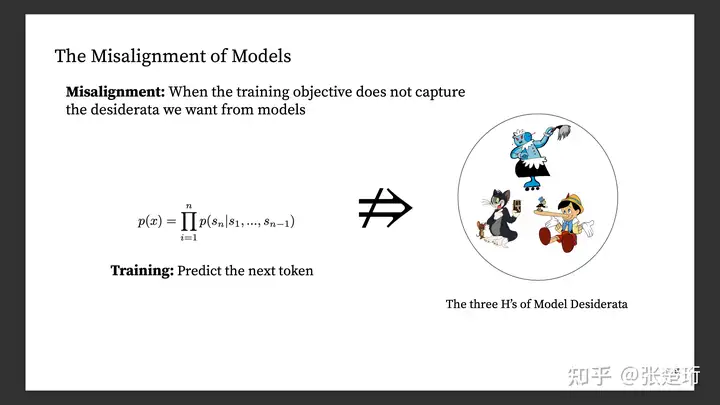
二、之前的工作¶

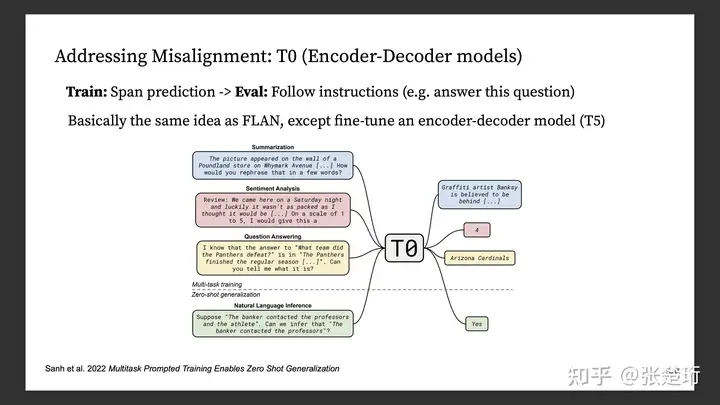
三、方法¶
这里使用的主要方法叫做 Learning from Human Feedback。大的框架是下面展示的三个步骤:1)人工收集一些示例样本,先有监督地训练一个模型;2)人工对于模型输出的候选结果作比较、打标签,从而训练得到一个奖励模型;3)使用这个奖励模型,用 PPO 算法(强化学习)来进一步对模型进行训练。
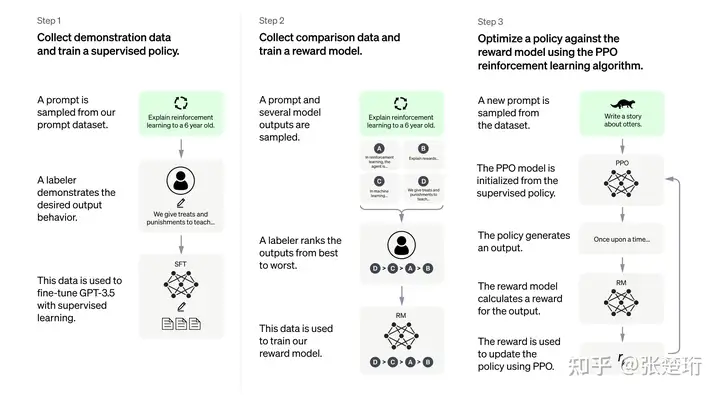
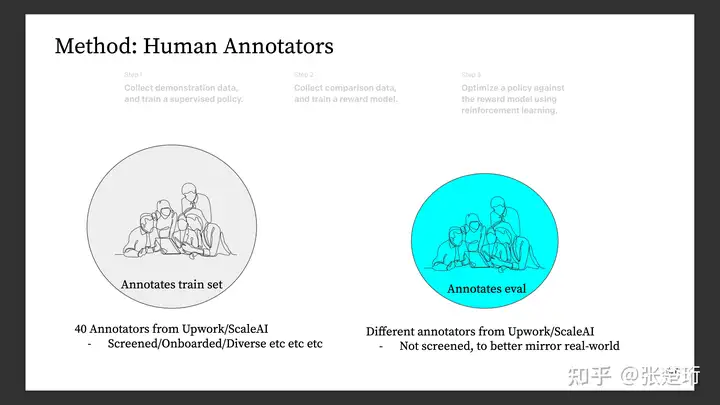
ChatGPT的价值取向归根结底来自于标注员的价值取向。因为标注员的数据不仅用于最开始的有监督 fine-tuning,而且用于训练一个 reward model,从而在后续的大规模强化学习训练中用于约束智能体的学习。
因此,OpenAI 只使用了 40 名全职标注员,从而方便他们形成一个统一的价值取向和标准。他们也会被筛查(screening),从而确保他们有正确统一的价值取向。
我们先来看一下第一步¶
首先,这里使用了一个来自于 OpenAI GPT3 Playground 的 prompts 的大数据集。下面列了一下 prompt 数据集的一些例子和大致情况。
不熟悉 prompt 的同学们可以粗浅理解它就像是“抛砖引玉”中的砖,你得先跟他讲一些东西,语言模型才好开口,不然涵盖了大量知识的语言模型也不知道从何讲起。
注意到,第一步和第二步是有监督学习,因此有 train-valid 的划分。

接下来,标注员会人工对于这些 prompt 进行示例回答,让语言模型去学习。这样,一个基本的 GPT-3 语言模型就被学习成了这里的 SFT 模型。

接下来我们看一下第二步¶
首先,对于每一个数据集中采样得到的 prompt,先前训练的 SFT 模型都会输出若干个选项,比如图例里面的 ABCD。

接下来,标注员会对于给出的候选输出进行排序。

原本的 prompt (x) 和标注员给的示例回答 (y) 就会用来训练一个奖励模型。我们希望被判定更好的输出得到的奖励数值要更高。由此,奖励模型可以通过最小化下面这样的损失函数来得到。

一个技术细节:要把 K choose 2 个候选对的比较放到同一个 batch 中做梯度下降,不然容易过拟合。

最后我们来看第三步¶
这一步的数据集都来自于 customer,数据集规模更大一些。这上面的训练就完全靠 reward model 自身的泛化能力来引导了。

在这一步的训练过程中,还不仅仅使用强化学习的优化目标(前面没有被框起来的部分)。还使用了下面的两个正则项来约束模型的表现。

最后,做一下总结:

关于方法的一些常见问题:
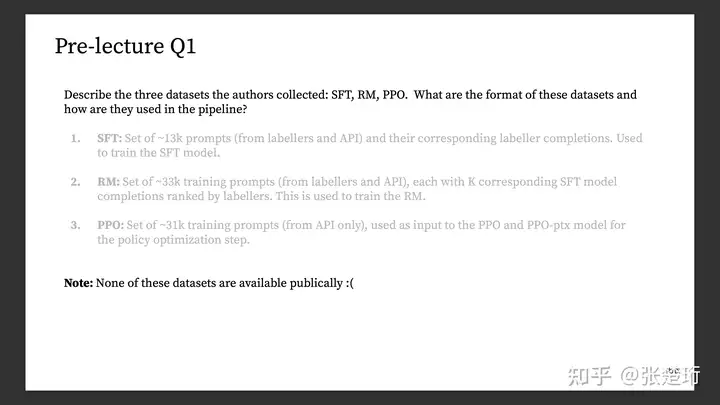
1、关于三个阶段所用到的数据集
2、关于方法的选择

3、我自己先前的一个疑问:前面的有监督学习过程,看起来似乎是一轮的,后续咋又要使用强化学习了呢?
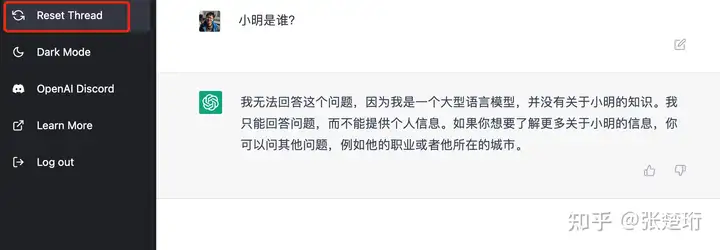
研究了一些,这里的对话看起来是建模成多轮的,前后对话有关联,在这一点倒是适合使用强化学习建模。 ChatGPT 里面专门有一个 Reset Thread 的按钮,可以看到这件事情。
四、实验结果¶
文章要在这三个 H (Helpful、Honest、Harmless)上对于模型做衡量,衡量方式如下:

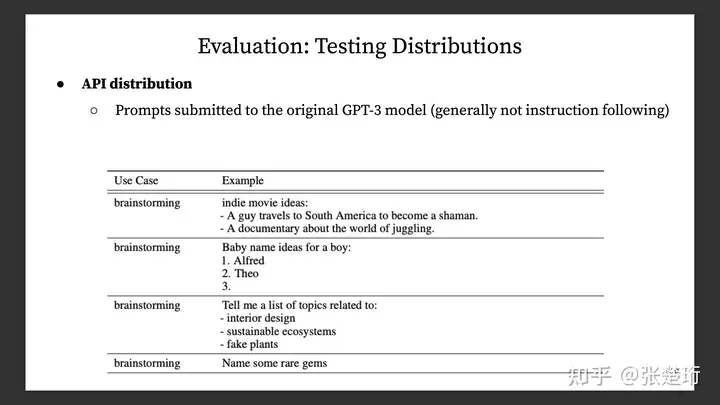
测试数据集/分布和测试任务:
注意到这里的 API 数据集就是之前 OpenAI 开放让大家试用的时候,收集到的大家奇奇怪怪的问题/输入(prompt)。


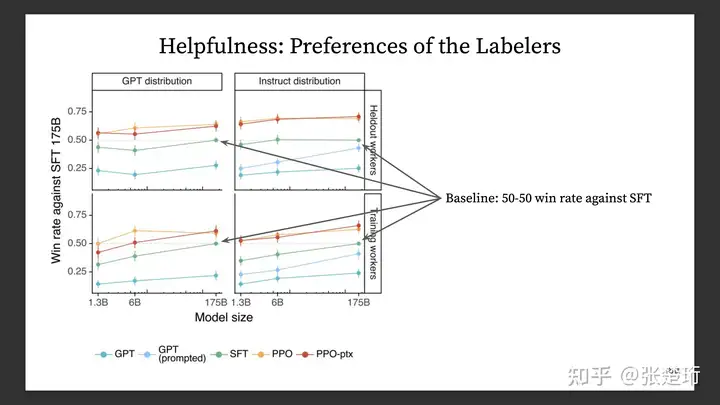
Helpfulness 测试
这个测试是通过标注员进行二选一的比较来进行的,标注员在待测试模型的输出和 SFT 模型的输出中选择一个更好的。如果得分为 0.5 则表示该模型和 SFT 相比性能差不多。
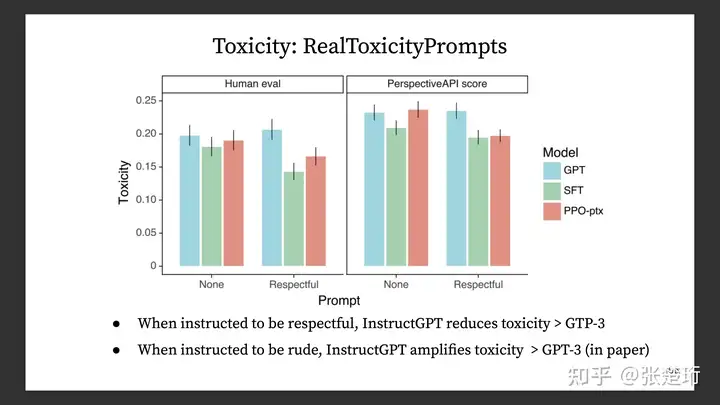
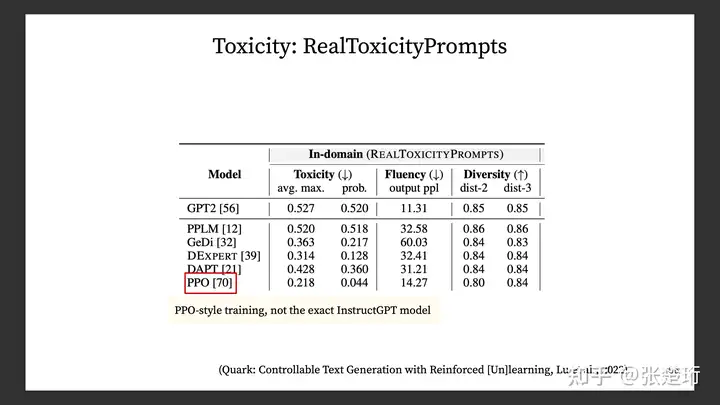
效果上来说,直接对于 GPT 加 prompt 也还不错,不过还是没有最后的 PPO-ptx 效果好。
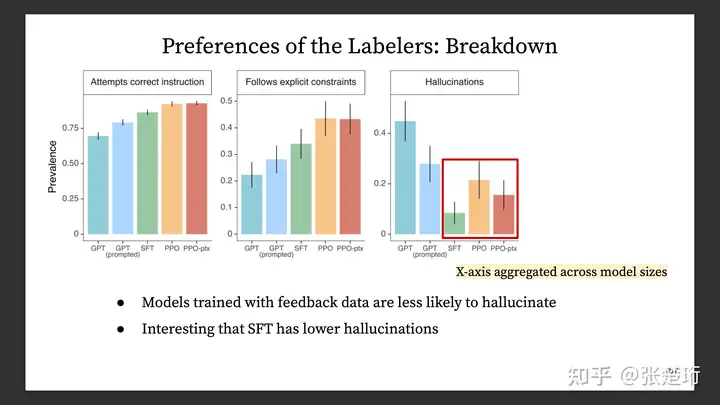
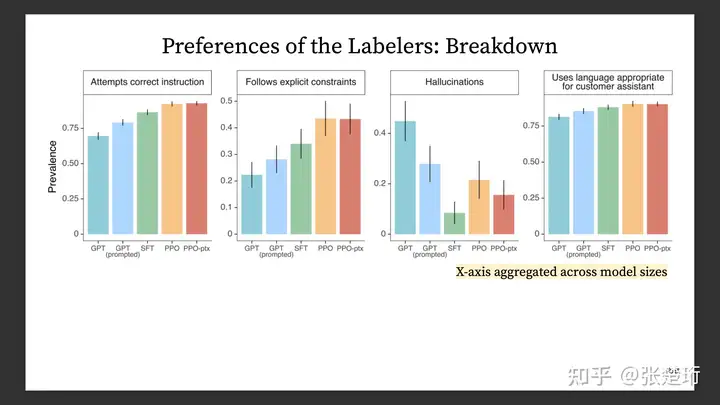
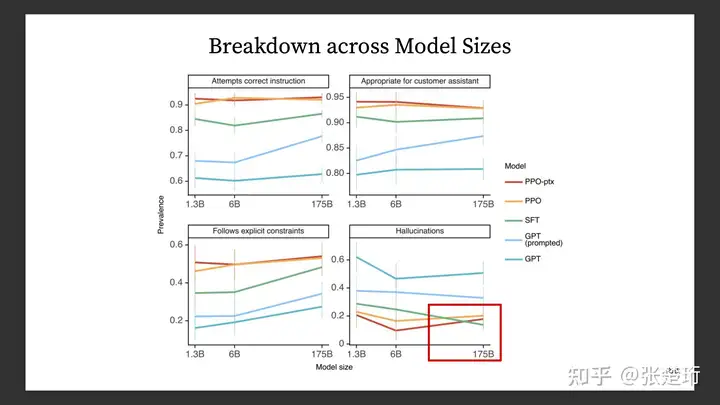
Helpfulness 在评价中是又下面这几项综合起来的,可以看一下他们分项的表现。使用示例样本进行有监督学习会使得模型更少地幻想(hallucination,凭空捏造信息),而基于奖励模型的 PPO 训练则会使得这样的幻想增多。此外,使用更大规模的语言模型也会使得幻想现象增多。

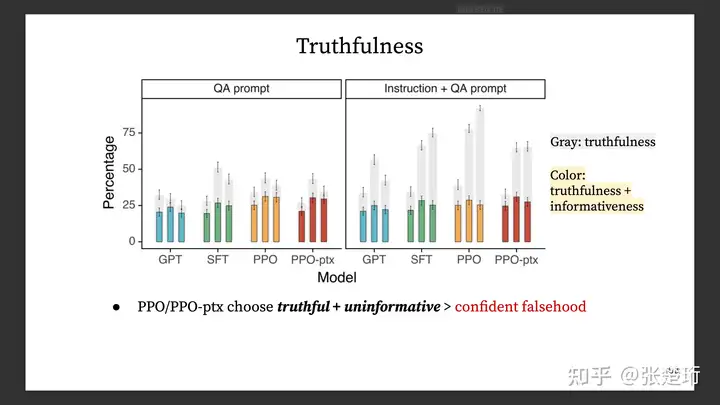
Honest/Truthfulness 测试
使用了 Instruction + QA prompt 来促使模型在不是非常确定的时候不要发表意见。

方法是在模型前加上如下这样的 instruction prompt:

Harmless 测试
类似地,方法也是加上如下的 prompt 从而减少模型产生有害/不礼貌/带有偏见的回答。 
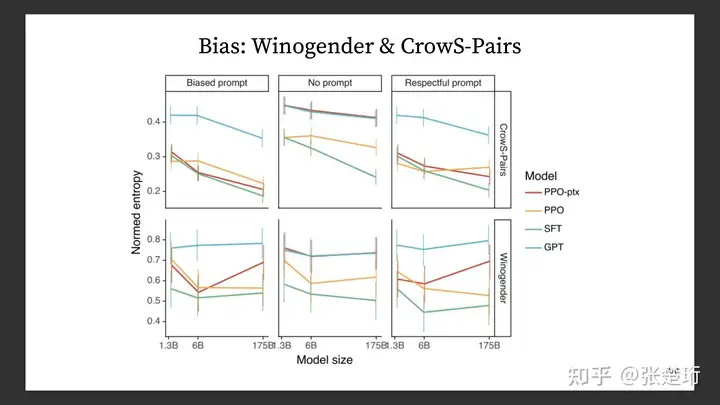
通过下面这些配对出现的 entropy 来衡量模型的 bias。 
一个总结:


缺陷之一:该模型会时常犯错。
有时候能算对,犯的错误还不太一样,并且是真人常犯的错误。关键是能用各种不同的方法来求解,确实牛,但是有些方法能走通,有些方法走一半搞错了。感觉这已经很强了。





五、总结¶


(来源:知乎,侵删)