ChatGPT技术精要,RLHF相关论文笔记(二)——Training language models to follow instructions with human feedback¶
本期论文链接: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2203.02155
这篇论文延续了上一篇文章讲的论文工作,继承了其中的主干思想部分,提出了InstructGPT。作为ChatGPT的前身工作,可以从中一窥ChatGPT训练的流程和技术细节。
问题¶
大型语言模型可以通过“prompt”执行一系列自然语言处理(NLP)任务,并给出一些任务示例作为输入。然而,这些大模型经常偏离用户的意图生成一些例如编造事实、有偏见或有毒的文本,或者根本不遵循用户指示。这是因为大模型的预训练目标是预测下一个token,而不是安全有帮助地遵循人类的指令。也就是“mis-align”的问题。
本文希望能提供一种方法,通过收集人类偏好数据来训练对齐人类和模型。
总体方法流程¶
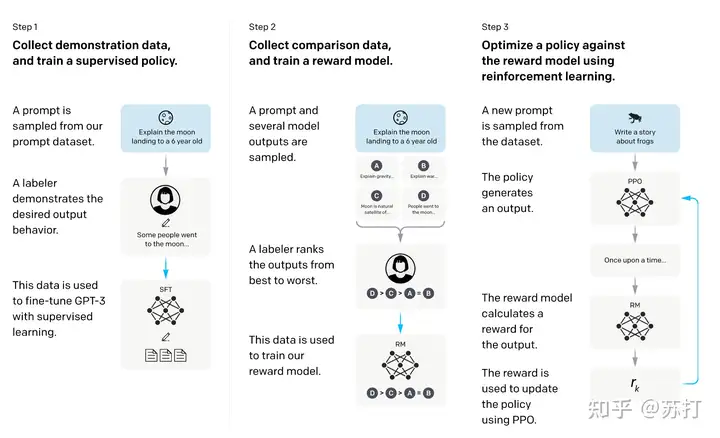
和上一篇论文的方法一样,流程具体分为三步
- 收集演示数据,并训练一个有监督的policy。微调的模型是GPT-3.
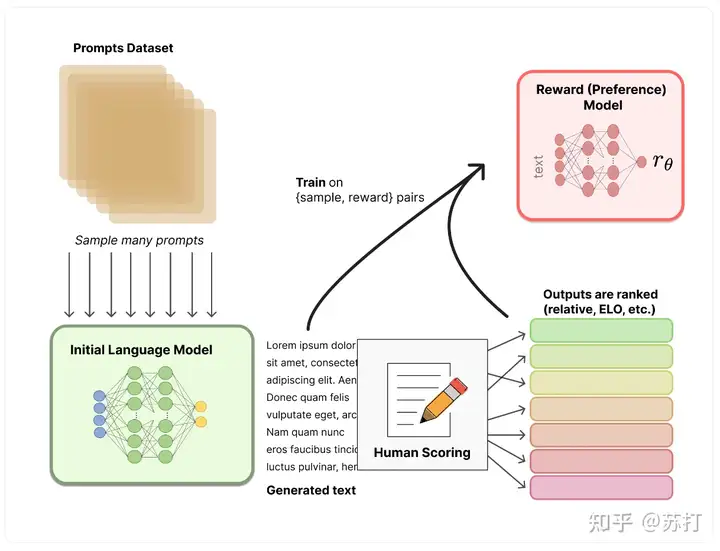
- 收集比较数据,训练一个奖励模型。作者收集了一个模型输出之间比较的数据集,其中标注者选择他们更喜欢给定输入的哪个输出。然后训练一个奖励模型(Reward Model ,RM)来预测人类偏好的输出。
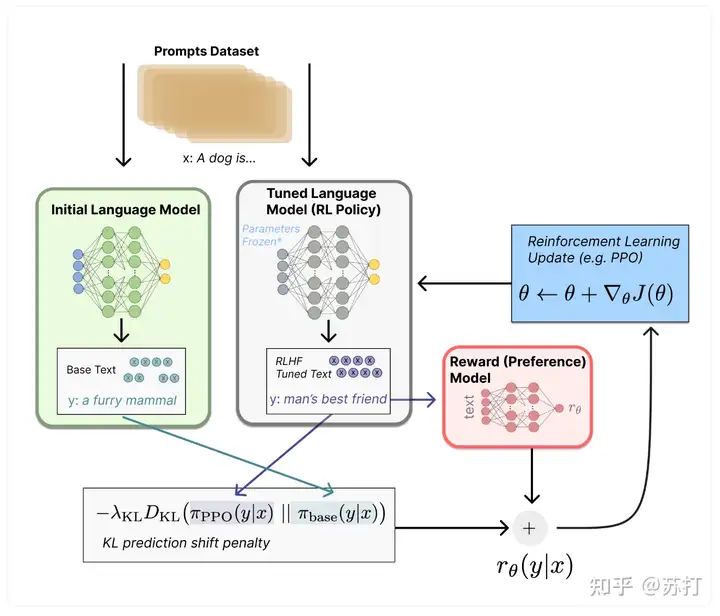
- 使用RM的输出作为标量奖励。使用PPO算法有监督微调policy以优化奖励。 2,3步是可以循环迭代的。
具体流程图放在下面:
数据集¶
那为了训练最开始的InstructGPT,需要召集一批人来人工编写prompt,OpenAI把这些人工编写的数据主要分为三类:
- Plain: 简单要求编写人员拍脑袋随便提出一个任意的任务,同时确保任务有足够的多样性。
- Few-shot: 要求编写人员提出一条指令(instruction),以及该指令的多个查询/响应对。也就是一个指令和其多个回答
- User-based: OpenAI征求用户的意见,把用户希望模型能完成的任务,未来能提供的服务列出waitlist,然后让编写人员根据waitlist,提出任务,编写prompt。
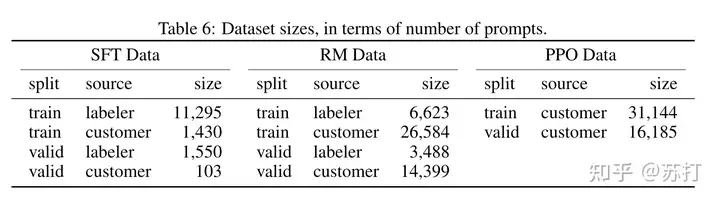
根据这些prompts,生成了三个数据集。labeler是由人工编写的,customer是由用户提交的。
SFT Data: 是用于模型第一步有监督微调的数据集
RM Data: 是用于模型第二步训练奖励模型的数据集
PPO Data: 是用于第三步进行强化学习训练所用到的数据集
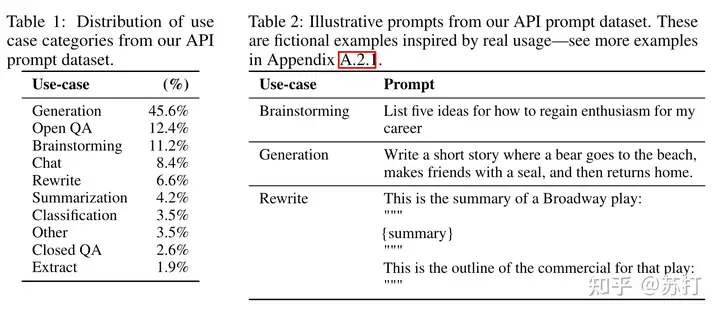
如下表所示,是用户提交prompt的类别分布,以及一些case。
模型方法¶
具体方法和前一篇的基本类似,但是其中多了一些细节。
具体流程图我们参考huggingface blog中的图。这里直接搬运一下。
一样的有监督训练,和之前的工作的发现一样,虽然在一个epoch之后监督模型在验证集上就出现了过拟合问题,但是继续训练对RM的评分和人类偏好评分上都有提升。
Reward modeling (RM)¶
方法上大致也是与上一篇一样,但是这篇文章为了加速训练,作者将K设置为4-9之间的数字,来进行排序。因为作者发现如果将每个单一组合作为单个数据点单独优化的话,在一个epcoh迭代后就会产生过拟合问题,因为相同prompt的组合是存在相关性的。
因此,作者把一个batch只设置一个prompt对应的组合,这样就不会产生一个配对就需要一次backward的问题,而是一个batch多个配对只进行一次backward。加快训练速度,也减少过拟合,提升了验证集的准确率。
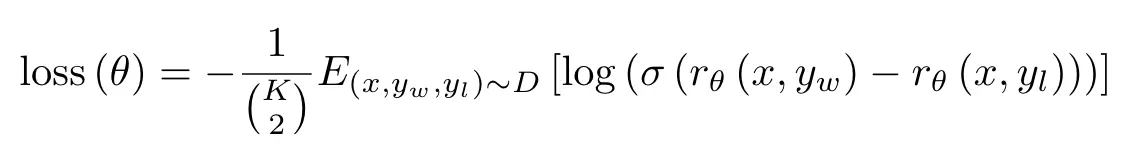
作者在使用6B参数的模型作为RM,一方面节约训练资源,且作者发现使用175B参数的模型作为RM训练会不稳定,不适合用作RM。
Reinforcement learning (RL)¶
具体方法也与前一篇基本相同,略微不同的是,作者尝试将预训练梯度混合到PPO梯度中,以使模型在公共NLP数据集上的性能退化减缓。记为“PPO-ptx”。
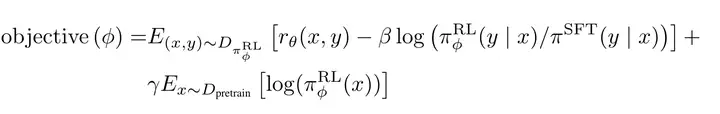
评估¶
要评估模型的“align”能力,首先要定义什么是对齐。作者认为“align”的意思是,模型能根据用户的意图进行行动,且输出的内容是有帮助和无害的。
因此,作者将评估定量地分为两个部分:
- 在API提交的数据集上进行评估。(数据未出现在训练集中)
- 在公开的NLP任务上进行评估。
结果¶
Prompt数据集¶
首先人类偏好性好于SFT的比例,可以看到PPO的两个模型显著优于后三个模型。
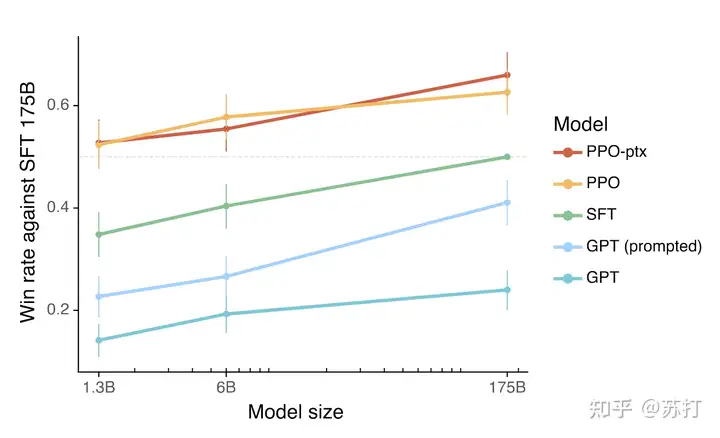
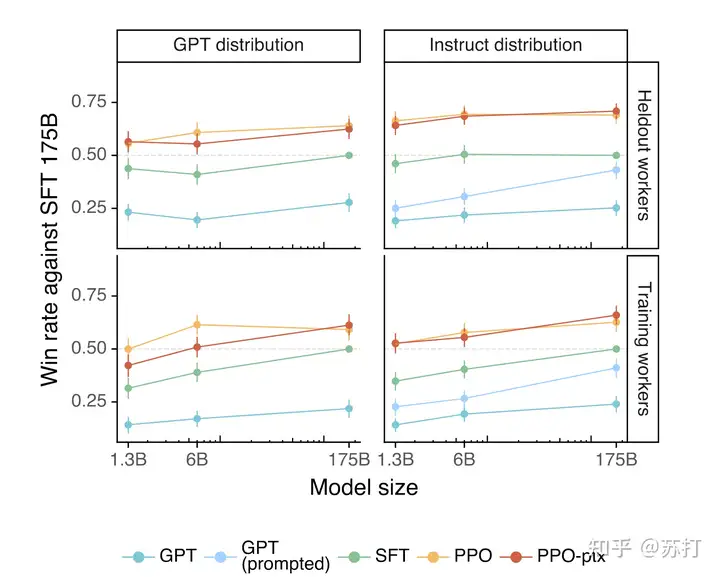
评价在和训练数据分布一致的测试集上的性能,左右分别是GPT-3和InstructGPT各自的主场。左边的测试数据是提交给GPT-3的,右边是提交给instructGPT上的测试数据。看到都是instructGPT碾压。
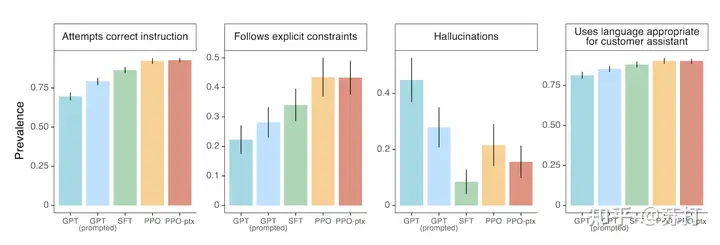
在四个维度上进行评估分别是,根据指令做正确的内容,遵循显式的约束,更少的编造事实(幻觉),对用户使用恰当的语言。在这四个维度上PPO的方法都显示出了比较明显的优势。
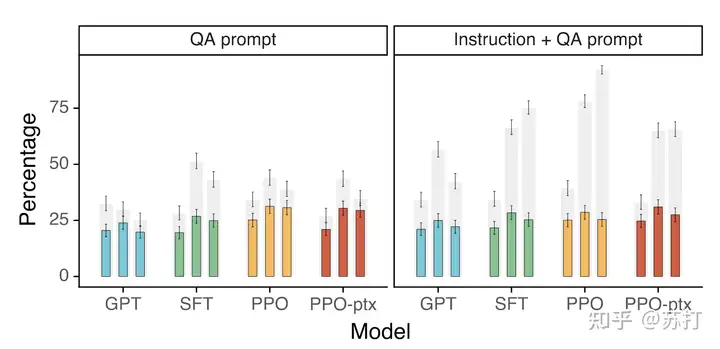
公开数据集¶
TruthfulQA dataset上的结果,灰色条表示真实性的等级;彩色条表示真实性和信息量的等级。
左图在大部分情况下PPO模型都比GPT-3更真实且有料;右图是加入了在模型不确定正确答案时”不予置评“(I have no comment)的模版,可以看到PPO会生成更多真实,但信息少的文本,说明PPO不会像GPT-3那样睁眼说瞎话。
RealToxicityPrompts上的结果。文本毒性和偏见评估¶
左图是人工评估,右边是自动指标评估,Respectful是加入了respectful prompt的结果。可以看到,不加respectful prompt的话文本毒性都会ppo的和GPT-3差不太多。加入之后PPO的文本毒性会显著降低。
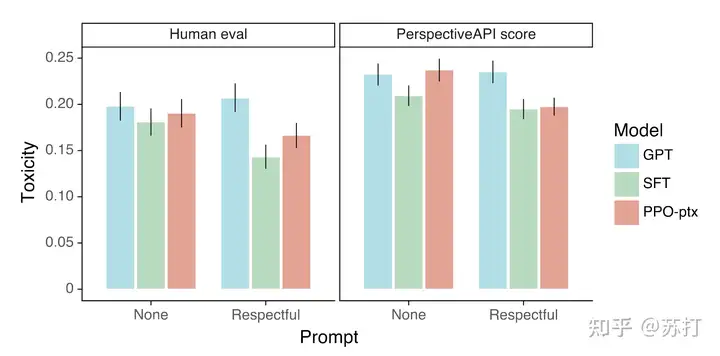
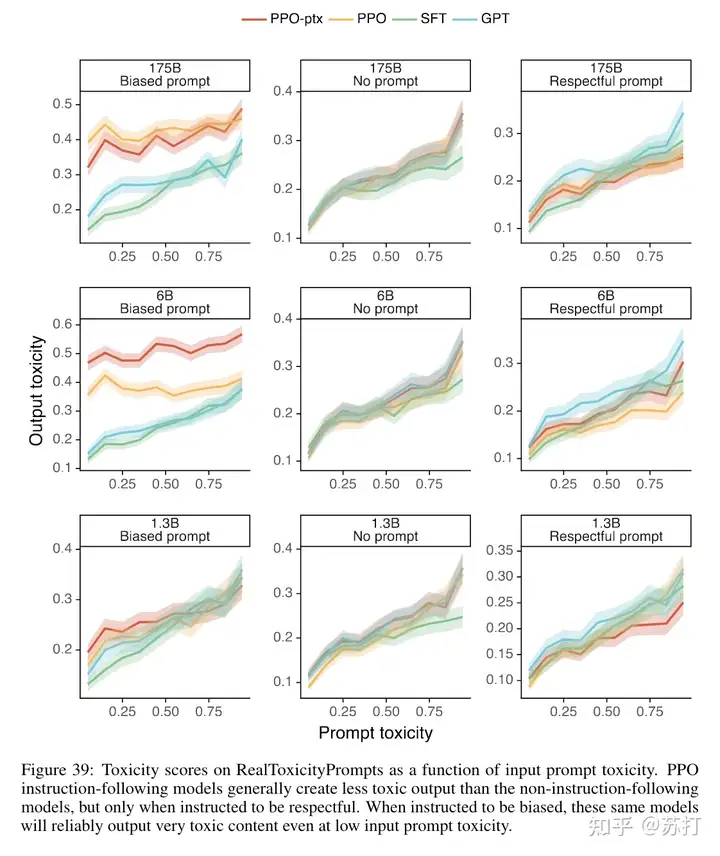
但是作者又对于不同毒性数据输入输出进行采样进行分析,说明其实PPO模型的毒性被夸大了。作者也分析了SFT模型虽然毒性低,但是它生成的内容也相较而言更短一些。
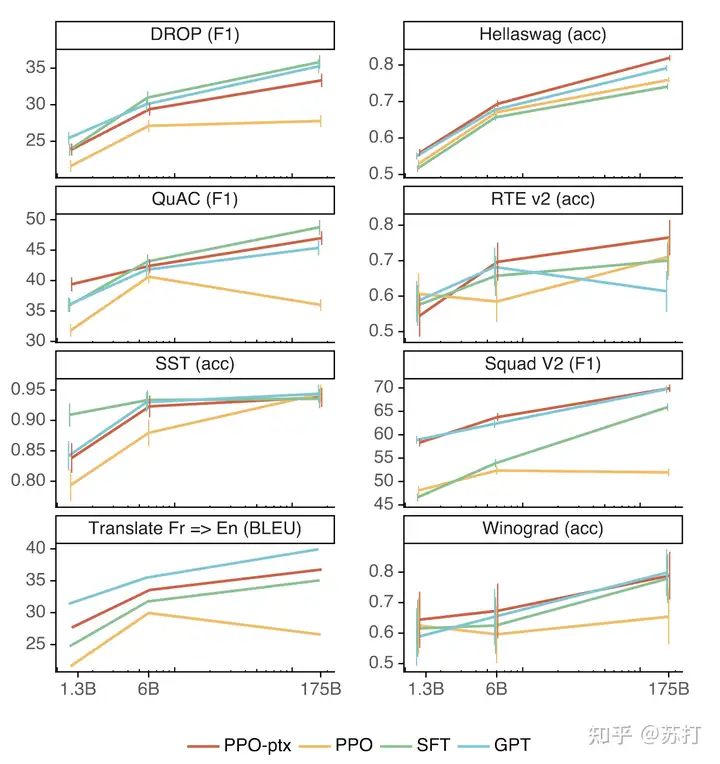
比较重要的是,作者提出模型PPO训练之后会因为“alignment tax”(对齐税)的问题导致模型在公开NLP数据集上的效果退化。但是通过在PPO训练过程中混入预训练梯度信息的方法可以缓解这一问题。
几个公开的NLP任务上few-shot的结果,可以看到PPT-pxt基本都显著好于PPO
定性分析¶
InstructGPT模型有很好的分布外泛化能力。¶
作者提到,instructGPT能在非英语问题也能很好回答,且也能在代码问题上进行回答。(非英语数据只占微调数据的极其小的一部分)比如下图两个case。但有时候instructGPT也会在输入是非英语问题时输出英语回答。而GPT-3虽然有时候也能回答这些问题,但需要更仔细的prompt引导。【是不是说明instructGPT对于prompt的鲁棒性更强】

InstructGPT依然会犯低级错误。¶
下表是两个例子,第一个问题是为什么冥想后要吃袜子。第二个问题是如果你以高速直接向南瓜发射炮弹会发生什么?

作者总结了ChatGPT会产生的一些错误
- 当给出的问题的前提是有问题的情况下,模型会顺着问题回答。
- 模型会过度反应,避免回答。当给出一个简单的问题时,它有时会说这个问题没有答案,并给出多个可能的答案,即使从上下文来看有一个相当明确的答案。
- 当instruction包含多个明确的约束(例如“列出10部1930年代在法国拍摄的电影”)或当约束对语言模型具有挑战性时(例如用指定数量的句子写摘要),模型的性能会下降。
作者怀疑1 的问题是原始数据集prompt里没有类似的。2 的问题是因为标注者更多地奖励模型要谦虚。这两个问题都可用对抗样本解决。
总结¶
这篇论文将chatGPT的大部分的核心技术细节都进行了讲解。说明了人机对齐的训练方法能够很好引导模型满足人类的偏好。作者也指出利用RLHF训练模型比训练一个更大模型对用户的满足度提升更大且成本更小,相比较于训练一个更大的预训练模型,如何利用现有的大模型来进行更多的研究才是当务之急。
RLHF的训练范式为技术的有效性和局限性提供了一个重要的反馈循环。另外如何把这种训练的范式进行推广,到更多的真实世界任务上去,也是未来研究的一个可以探索的方向。还有就是再进化,这种训练方式的天花板就在human本身,有没有办法突破人类极限,超越人类。这是更让人无限畅想的未来。
(来源:知乎https://zhuanlan.zhihu.com/p/604534719 侵删)