ChatGPT技术精要,RLHF相关论文笔记(一)——Learning to summarize from human feedback¶
论文链接: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2009.01325
这篇工作是OpenAI早于ChatGPT两年发表在NeurIPS 2020,在这篇文章中ChatGPT的框架雏形已经显现。文章专注于英文摘要任务,所用的方法和ChatGPT基本一致,包括了ChatGPT的核心方法,RLHF(Reinforcement Learning from Human Feedback)。
问题¶
随着语言模型变得越来越强大,训练和评估越来越受到用于特定任务的数据和指标的限制。例如,摘要任务训练模型使用ROUGE等一些自动化指标进行评估,但这些指标都不能完全刻画我们对摘要质量的需求。传统的通过监督学习和最大化对数似然并不是一个好的方法。因为在摘要、翻译等任务中,可能同时有几个相差很大的输出文本都是高质量的输出,而最大化对数似然只会迫使模型输出去接近训练集reference里的那个版本的文本。
这篇文章专注于英文摘要任务,不采用极大化词的对数似然损失,而是利用收集到的human feedback数据通过监督学习专门训练一个打分模型来直接捕获人类的偏好,然后再使用这个模型通过强化学习来训练生成模型。
方法¶
第一步:¶
收集多个候选的原文-摘要对数据【基于当前策略,初始策略,原文摘要,以及其他不同baseline生成的数据】,并成对发送给标注人员来选择最佳的那一个。
第二步:¶
利用第一步标注好的数据来训练一个Reward Model来模拟人类偏好。
第三步:¶
利用第二步训练得到的Reward Model输出的logit来引导强化学习过程,训练摘要生成模型。
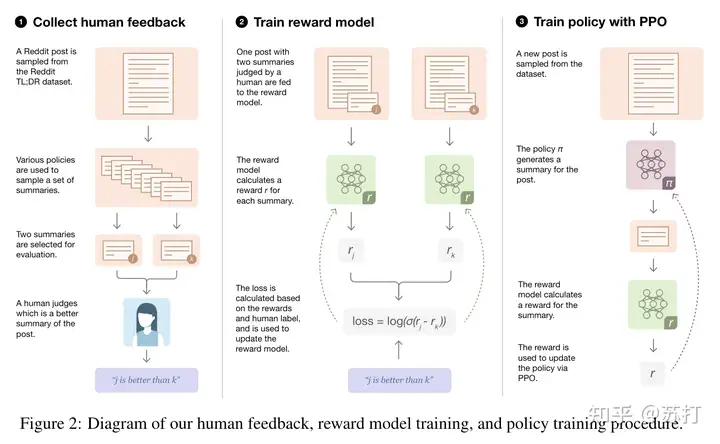
数据集¶
来自reddit的TL;DR摘要数据集,包含3M的poster文本,以及原文自带的摘要。对数据集进行一系列的数据预处理。过滤只留下人工编写的摘要包含24到48个token的帖子,以最大限度地减少摘要长度对质量的潜在影响。最终数据集包含123,169个帖子。
任务¶
摘要生成任务,摘要长度尽量不长于48,且质量尽可能的好。判断摘要好坏的标准是,摘要是否忠实地将原文转达给只读摘要不读原文的读者。
收集人类反馈¶
之前的关于根据人类反馈微调语言模型的工作报告了一个“我们希望模型学习的质量概念与人类标注者实际评估的质量概念之间的不匹配”的问题。导致的结果就是,模型生成的摘要在标注者看来是高质量的,但在研究者看来是低质量的。
具体流程不细讲,但是我认为是这篇工作中最重要的一环。(大概全部离线进行,然后就是时刻保持专家与标注者的对齐沟通)
最后的一致率数据也很好,专家与标注者之间的一致率有77%,专家之间的一致率有73%。
模型方法¶
主干的初始模型采用GPT-3结构的模型,选择了1.3B和6.7B两个参数量的模型上进行Human Feedback的实验。
首先,对两个模型做LM的自回归预训练。
第二步,对模型在构建的摘要数据集上进行有监督的fine-tune,得到监督模型。使用这些监督模型对初始摘要进行抽样,以收集比较,初始化policy和奖励模型,并作为baseline。
第三步,在监督模型的基础上进行奖励模型(RM)的训练,是在其上增加一个输出标量的线性head得到的。训练结束后将reward模型输出归一化,以便来自文章数据的参考摘要达到0的平均分。
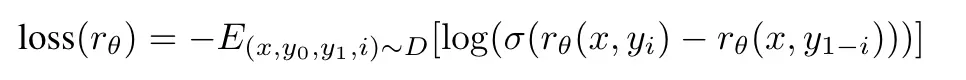
第四步,利用强化学习训练。用于生成最后结果的模型(policy model)是另一个fine-tune过的模型。通过将奖励模型的输出作为使用PPO算法最大化的整个摘要的奖励,其中每个时间步骤都是一个BPE token。只有在整个摘要生成完之后才会有可用于监督信号的reward,在一个个词往出蹦的时候是没有任何监督信号的。
比较重要的是作者在Reward中加入了一个KL散度的惩罚项。作者认为,KL惩罚项有两个好处。
- 可以作为一个熵奖励,entropy bonus,鼓励policy进行探索,防止其坍塌到单一模式。【强化学习的一些知识】
- 确保policy不会学习产生与奖励模型在训练期间看到的结果有太大不同的输出。【防止模型训飞了】
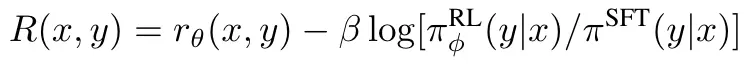
结果¶
首先给出一个case,如下:

可以看到,通过RLHF训练的模型已经达到近似人类摘要的效果了,而监督模型出现了很明显的事实不一致问题。
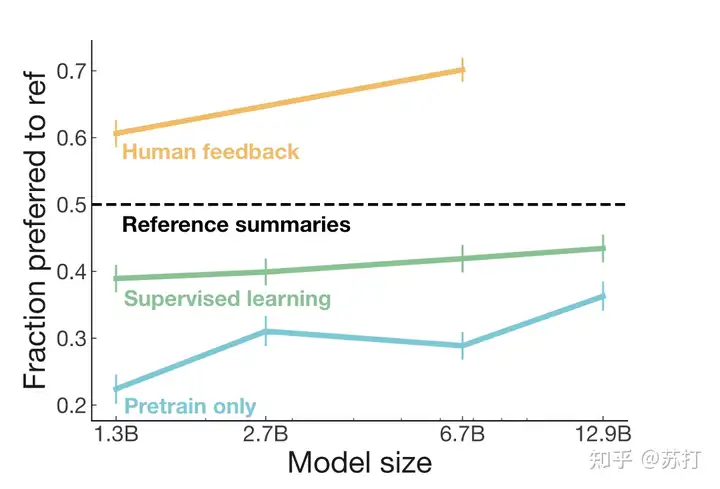
人工评估最喜欢的输出,纵坐标是被选为最喜欢的比例。可见HF的结果大大超越了监督学习的结果。
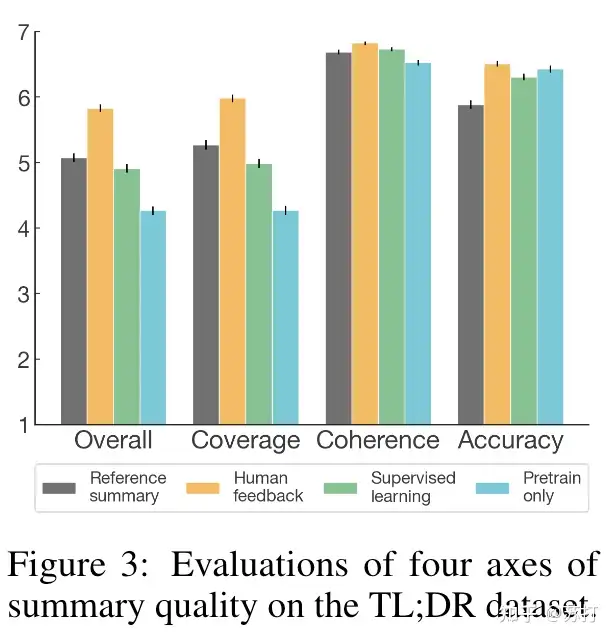
标注人员使用7点李克特量表在四个维度(或“轴”)评估摘要质量【分别是,覆盖度、准确度、流畅性、整体质量】,发现HF模型在四个维度上都领先,且在覆盖度上尤其优秀。
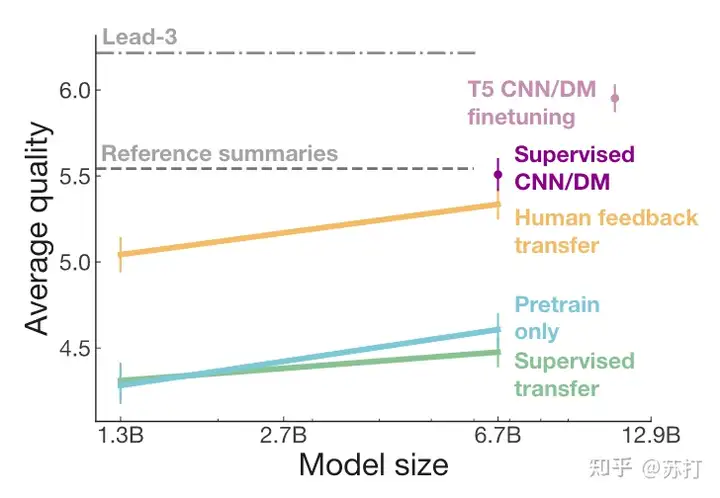
泛化性评估。评估模型在其他数据集上的迁移能力(OOD)。虽然HF在训练时有生成长度的限制,但是从结果可以看到,模型的效果基本和相同结构模型在目标领域数据上训练的结果一样好,比另外两个模型好出一大截。
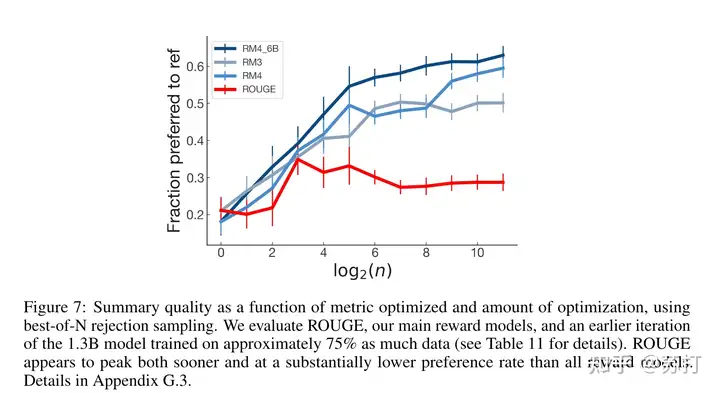
利用ROUGE作为reward来优化模型,人类评估效果上会很快就达到峰值,并稳步下降,收敛。效果相比其他RM的差了很多
一些发现¶
作者发现RM对于模型中一些重要的语义细节很敏感。作者为此构建了一个数据集对其中的摘要进行最小限度的编辑以进行改进。发现RM更喜欢编辑的摘要占比是(1.3B为79.4%,6.7B为82.8%),几乎与单独的一组人类评估者(84.1%)一样多。
总结¶
虽然作者提出的方法效果非常好,但是作者在文末也承认了这篇工作的方法资源消耗巨大,达到了320 GPU / 天和数千小时的人工标注时间。这个成本确实不是一般研究团队所能承受的了的,目前来看对于硬件,人力成本和时间成本的消耗是其最大的局限性。但是其应用前景非常广阔,给模型注入人类的偏好,让大模型更好地对齐人。ChatGPT的巨大成功也证明了这一方法可行性。
(来源:知乎https://zhuanlan.zhihu.com/p/604375990 侵删)