为什么ChatGPT可能代替Google - ChatGPT技术详解¶
什么是搜索引擎¶
在本文的最开始我们先回顾一下我们为什么需要 Google 这样的搜索引擎。我认为从搜索需求层级上可以分为
- 从海量信息中查找特定内容,如 Youtube/TikTok
- 没有已有的特定答案,但是知道通过什么步骤能得到特定答案,如 wolfram
- 没有已有的特定答案,并且没有明确的步骤得到特定答案
当我们想看《三体》,那我们的需求只到第一级,即只需要返回给我特定内容即可。
我们需要计算 pi 的第 10 次方,网上可能没有直接答案,但是可以通过特定步骤计算答案,即为第二层级的需求。
我们想要用英语写一封咨询 ChatGPT 技术的邮件,网上没有直接答案,并且创作难以分解为明确的步骤,即为第三层的需求。
现在的搜索引擎¶
为了实现上述的三个层次的需求现在的搜索引擎一般需要具有下述流程,这里已经进行了大量的简化,实际每一步都非常复杂需要大量的工程算法工作。 对于第一级需求只需要返回一条最相关内容即可。对于第二层级需求要找到最适合他的外部模块,再通过外部模块计算结果。对于第三层级需求不但需要外部模块,可能还需要结合多个已有内容的知识生成新的内容。
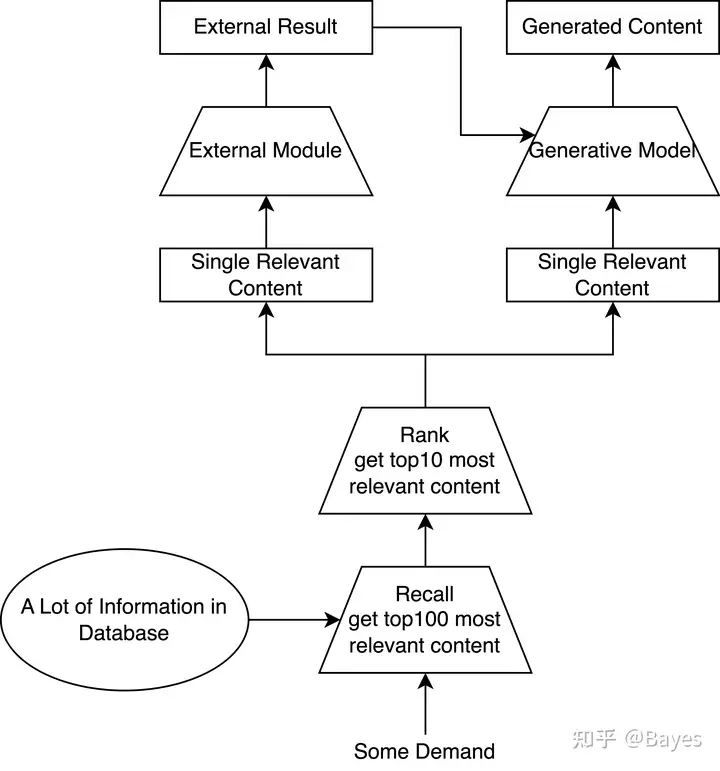
ChatGPT 当作搜索引擎¶
可以看到 ChatGPT 抛弃了传统搜索引擎中的多阶段方式,而是使用端到端的方式将所有计算都放在模型中实现,不再显式的区分召回/排序/抽取等阶段;并且实现存算一体,不再显式建立一个大的数据库存储知识,而是直接将知识存储在模型参数中。 可以看出 ChatGPT 实现了一个前所未有的端到端模型,之前的端到端大部分还停留在比如:NLP 不再做句法分析/CV 不再做手工特征提取,而 ChatGPT 实现了多个模型/算法的融合。
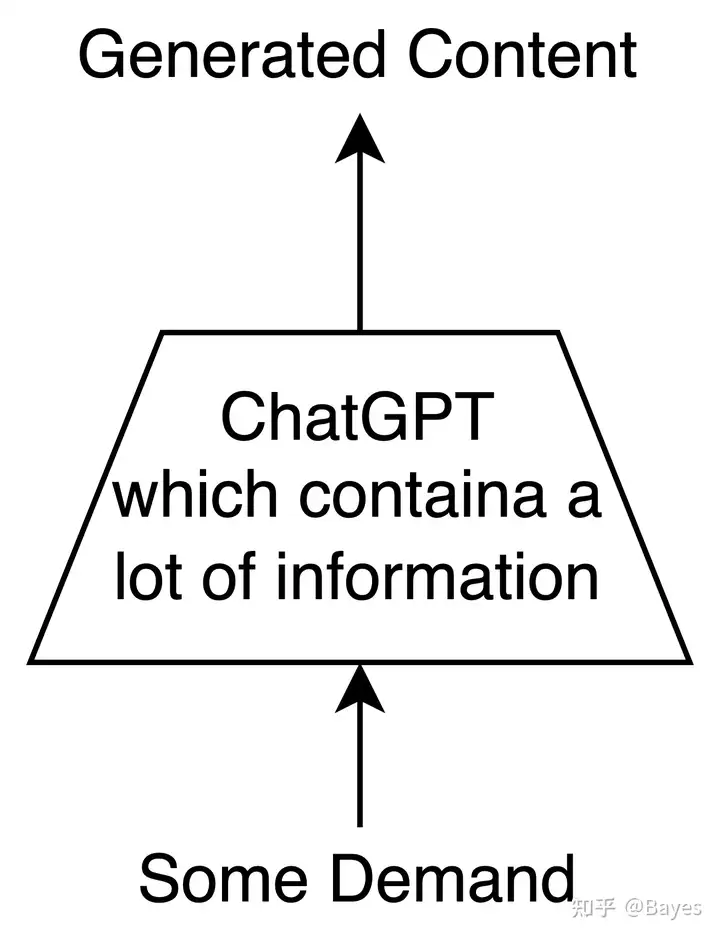
为了实现上面所说的功能我们很容易能想到他需要哪些前提
- 为了实现端到端计算需要强大的表达能力
- 为了实现海量信息的存储需要巨大的参数量
- 为了实现这个特殊的任务需要特殊的训练方式
我们将在下面分别介绍这几点。
两者的对比¶
- 首先从上面的分析我们可以看出现有搜索引擎返回主要还是已经存在的内容,这同时对返回结果的正确性/时效性等有一定的保证;而 ChatGPT 的结果经过了他自行转存,这里仍然是一个黑盒,正确性无法保证,同时由于不更新也难以保证时效性。因此对于第一层的需求现有搜索引擎应当有更好的结果。
- 对于第二层需求,现有模型的错误主要来自于将需求解析成外部模块可处理的输入时的错误,而 ChatGPT 除了这一可能的错误外还因为没有引入一个外部模块,可能导致自行处理计算的错误,比如现在 ChatGPT 的计算能力一般。
- 从第三层级来看,ChatGPT 实现了端到端的预测方式,并且引入了 RLHF ,生成方面能力应当是远超现有搜索引擎的,毕竟现有搜索引擎完全没有这方面能力。
从上面的对比也可以看出一些 ChatGPT 可以做的方向
- 理解 LLM(Large Language Model) 如何存储组织知识,如何在 LLM 中更新加入新知识,如何提取这些知识
- 在 LLM 模型中适当的引入 external module,毕竟很多领域已经有了现成工具
- 如何生成更自洽的结果,如何加快自回归模型的速度
如何学到海量知识¶
模型¶
我们首先介绍一下使用的模型 GPT,其实 GPT 本身没有太多复杂的东西,我们仅简单介绍一下Transformer 相关介绍可见 The Illustrated Transformer
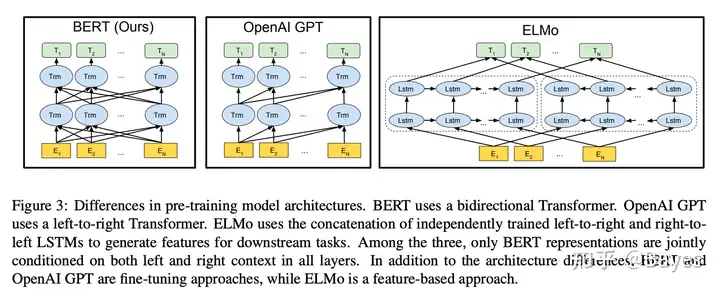
模型结构如上图,图片来自 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding。可以看出 BERT 和 GPT 的差异主要是 Attention 是否双向可见,在 BERT 中 Attention 为双向的,而在 GPT 中 Attention 仅单向可见。具体实现也很简单仅需在计算 Attention Map 后减去一个三角矩阵,这样可以实现前面的 token 对后面的 Attention 为 0,实现单向注意力机制。
在模型结构之外 BERT 和 GPT 的预训练任务也有一定的差异,BERT 的预训练任务一般为 MLM,即 masked language modeling,在输入中将一部分 token 置为[MASK],然后再输出端还原这个词。而 GPT 的任务为 language modeling,即单向的预测下一个词,loss 可以使用交叉熵。
具体的实现可以见 minGPT github。 GPT2: Language Models are Unsupervised Multitask Learners GPT3: Language Models are Few-Shot Learners OPT: Open Pre-trained Transformer Language Models LaMDA: Language Models for Dialog Applications PaLM: Scaling Language Modeling with Pathways
数据¶
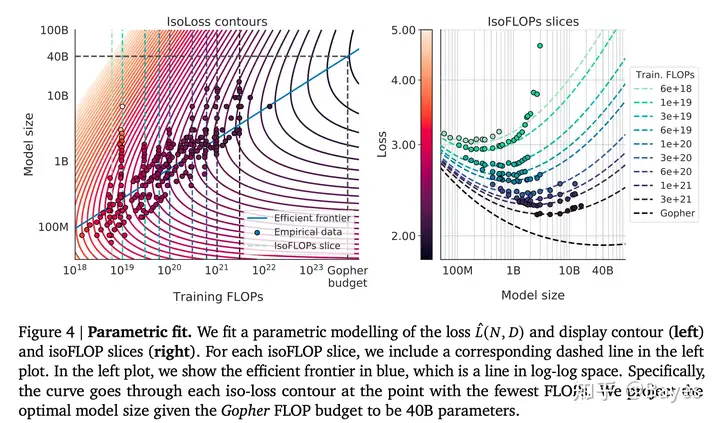
众所周知,数据决定了一个模型的最终表现,而数据又有两方面:数量和质量。之前的大部分研究都是保持数据不变的情况下增大模型参数量,或者反之。我们都知道无论增大两者中的哪一个都会导致所需要的计算量增加,那么一个接下来的问题就是当保持一定的计算量时,应该如何权衡模型大小和数据大小。这篇文章 Training Compute-Optimal Large Language Models 就研究了这个问题,参考下图右图可以看到当保持一定的计算量时模型效果随着模型大小增大先提升后下降,这也符合预期,毕竟最后只有几个样本无论模型再大效果也不会好。
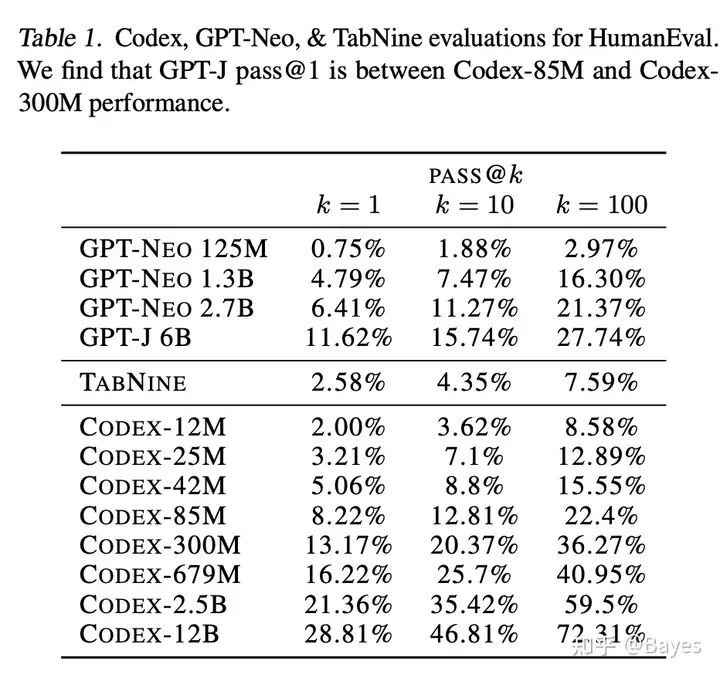
除了数量之外数据质量同样重要,到底什么样的数据能够得到最好的性能呢?在这片文章中 Codex: Evaluating Large Language Models Trained on Code 有一个令人惊讶的发现,在训练数据中加入代码可以显著提升模型的推理能力。可以看到加入代码后即使 300M 的模型也能达到原本 6B 模型的效果。我估计最初的作者也没有料到这个效果。当然本文主要是在一些推理任务上的效果,在其他任务上不一定有增益。因此,如何评估数据质量,什么数据适合什么任务还是一个有待研究的问题。
性能¶
计算量估计¶
由于 GPT 为自回归模型,每次预测下一个 token,因此在 inference 时如果要预测长度为 N 的序列需要进行 N 次的前向计算。下面我们简单分析一下 inference 时的计算量以及思考一下如何减少一些计算量。先设定一些参数 H: Hidden size T: Sequence length

An Attention Free Transformer
总结¶
从效果来看:观察 BERT 和 GPT 可以发现,理论上 BERT 可以通过 position embedding 实现 GPT 的效果。目前所说的 GPT 在生成任务上优于 BERT 我认为更多是预训练任务所带来的,因为目前所说的生成任务一般是给定前文生成后文,这和 GPT 的训练数据是对齐,BERT 虽然也能通过把[MASK]放在最后实现自回归生成,但是毕竟数据分布上有一定的差异。不过如果是一个"给定故事的开头和结尾生成中间"这样的任务 GPT 就不再那么对齐了,可能 BERT 这样双向的反而更好。所以不同于通向 AGI 之路:大型语言模型(LLM)技术精要中 GPT 一定优于 BERT 的观点如果从效果上来看我认为单向不一定优于双向。
从性能上来看:根据上文对性能的分析单向的优点主要在于序列预测时可以节省大量的计算,对于工业应用来说这是很重要的,因此从这方面我认为可能 GPT 会是更适合的结构。
如何提取已有的知识¶
Prompt¶
prompt 概念在 GPT-3 论文中被提出,在文中使用 Prompt 的能力叫做 in-context learning。下图是一个使用 prompt 和标准 finetune 的对比。可以看出在 prompt 中不再更新模型的参数,而是通过任务描述/示例加入上下文让模型获得处理新任务的能力。这种方法在 zero-shot 和 few-shot 中具有较好的表现。
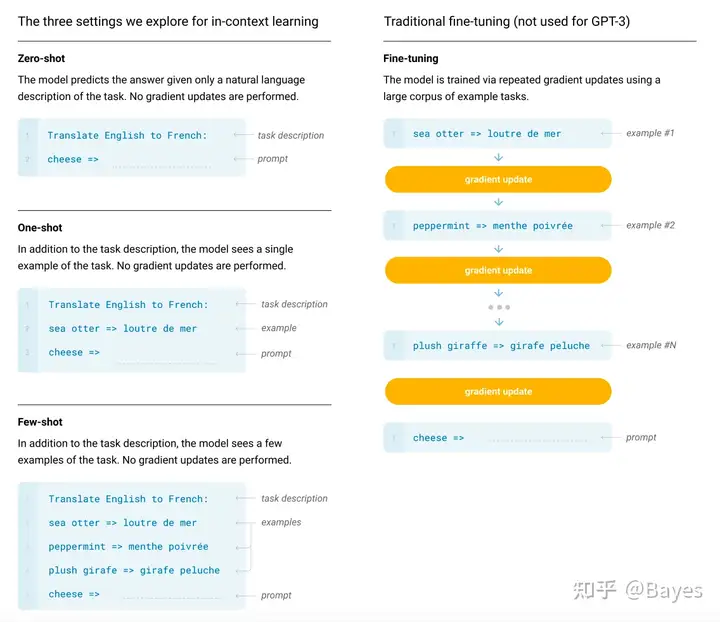
这里 prompt 本质是将下游任务转变为和预训练阶段数据分布类似的形式,使得模型能够充分发挥预训练阶段的能力。是一种 align 预训练任务和下游任务分布的方法。 - Finetune: 调整模型的参数,使得模型适应下游任务的分布 - Prompt: 调整输入的分布,使得下游任务的数据适应预训练数据的分布
一些具体方法可见下面两篇文章,但是我认为在后期的如 Prefix-Tuning 方法已经和最初的 Prompt 方法的思路不一致,实际更接近 Finetune。 一文了解 Prompt 的基本知识与经典工作 提示学习 Prompt Tuning:面向研究综述 可以看到其实 Prompt 本身并不是非常复杂的技术,实际还有点简单,但是大家都觉得他实在太简单了导致没人这么尝试过,所以还是得拓宽思路,简单的方法更应该快速的试一下。
Chain of Thought¶
虽然 Prompt 是一个简单有效的适应新任务的方法,但是 GPT 系列模型在最开始使用 Prompt 的效果也没有那么好,相比于 Finetune 方法还是有明显的差距。同时最开始的 Prompt 也是比较简单的,研究人员认为对于有些复杂的推理问题是不是应该让模型也写一下过程呢?毕竟好记性不如烂笔头,所以在 CoT: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 中研究者提出了 Chain of Thought 的方法,方法也是很简单,参考下图左一看就明白。
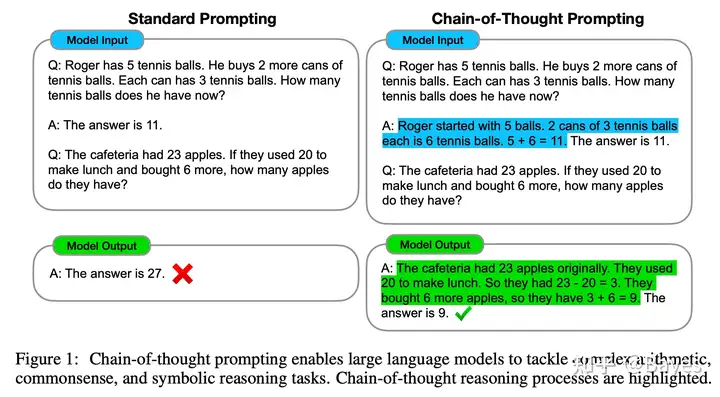
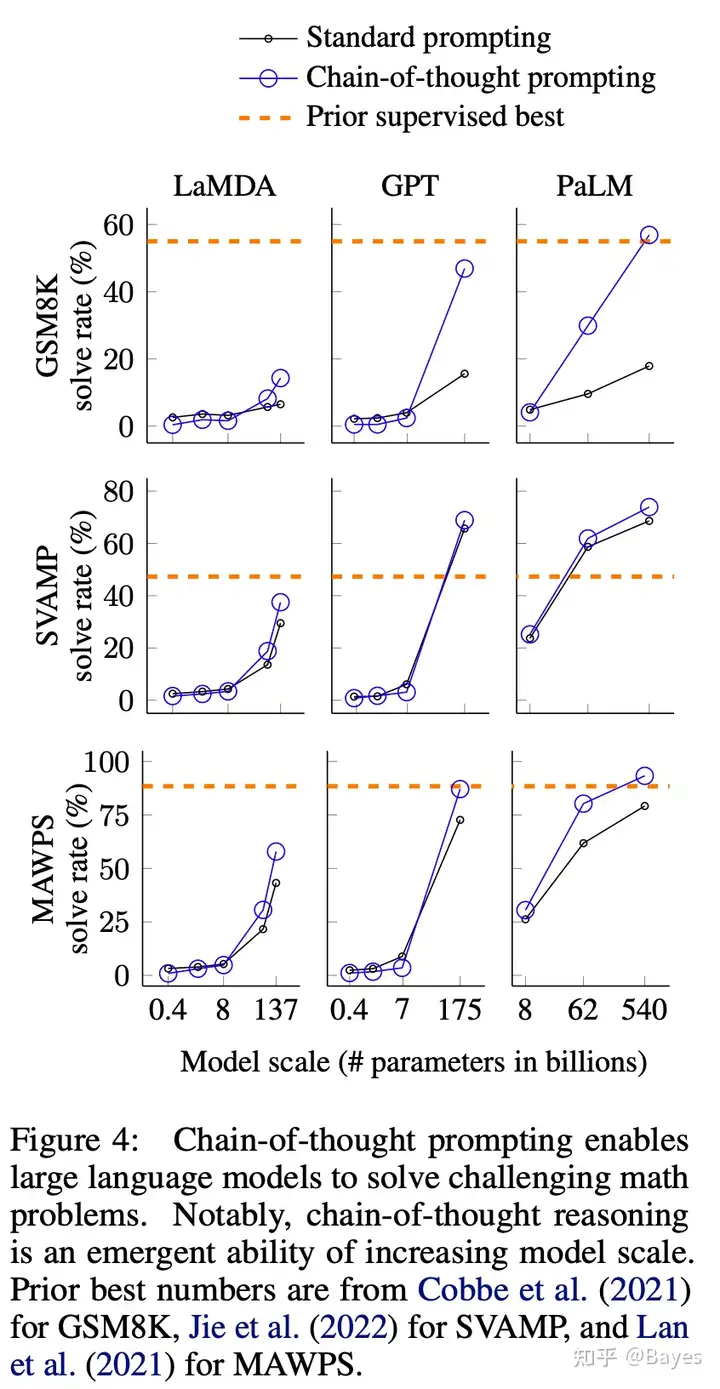
并且这样简单的方法取得了突出的效果,参考上图右,在多个推理任务上 CoT 相比于 Prompt 有明显的提升。甚至当模型增大到 175B 时表现出了超出 Finetune 的效果(虽然这个 Finetune 的估计没有 175B 这么大)。这一能力也被称为涌现能力 Emergent Abilities。
在早期研究认为模型的能力和模型参数量之间存在一定的关系,大致服从测试效果和模型参数的对数呈正比例关系,如下图。Scaling Laws for Neural Language Models
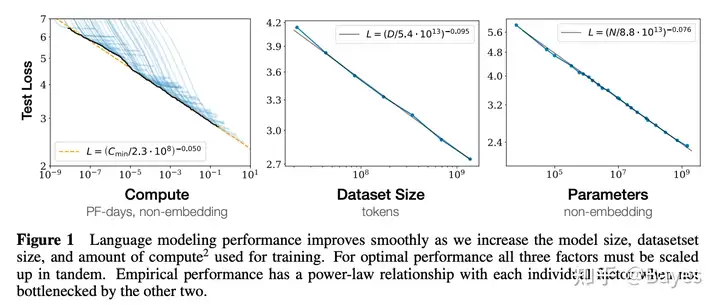
那么按照这样来估计在一些复杂推理任务上即使模型有数量级的提升,最终效果的提升仍然有限。但是参考 CoT 的效果可以发现在参数量较小时,跟对数正比基本吻合,但是当到 100B 以上时出现了效果的突增。也正是这一点领研究者认为 CoT 或者 Prompt 这样的方式未来会超过 Finetune。Emergent Abilities of Large Language Models
在深入理解语言模型的突现能力中分析了更多涌现能力的例子,除了上面的推理能力文章指出 LLM 还减少了对外部数据的依赖
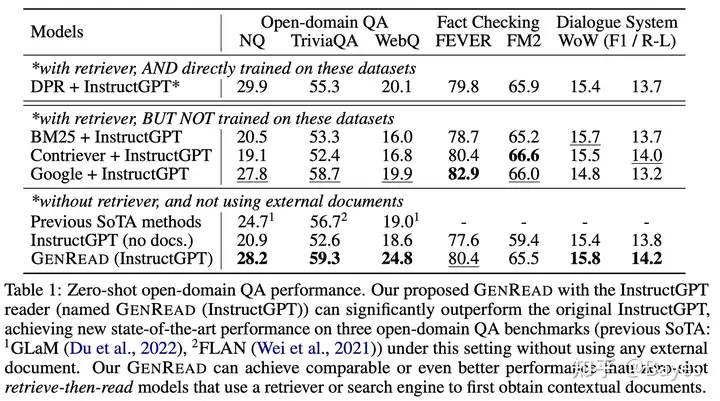
对于大型语言模型,可以直接去掉检索器,仅依赖模型的内部知识,且无需精调
参考下图我们可以看出即使不使用额外的检索器模型也能取得较好的效果。但是同时我认为这也是一个问题,当模型内部知识和外部知识存在分歧时 LLM 是否会因为过强的内部知识导致错误,在下图中可以看到使用 BM25 和 Contriever 的效果相对于只有模型并没有什么提升,甚至在一些任务上有些降低,我认为这也佐证了上述担忧确实存在。
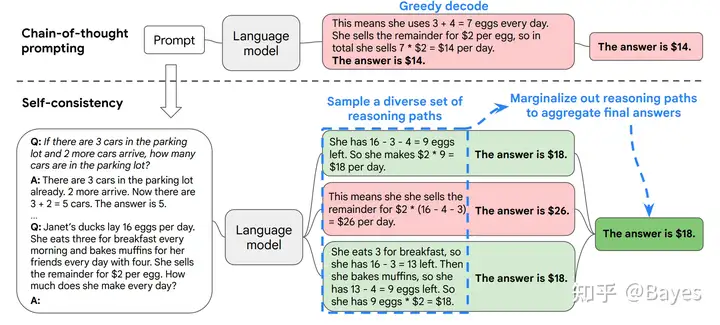
CoT 的想法就是让模型不直接预测最终结果,而是给出一种中间过程,那么一个问题往往可以有多种解法,我们是否可以使用多种解法的结果做一个汇总来得到更准确的答案呢?这也就是下面这篇文章的做法 SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS。
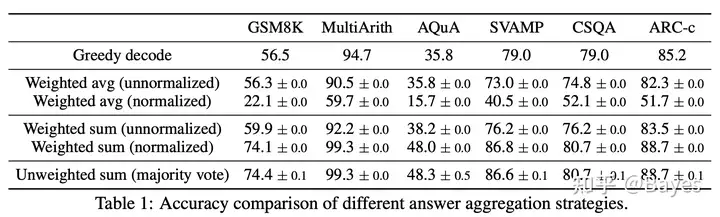
通过不同的思维链使得结果又有明显的提升。
CoT 如何生效¶
上面提到的 Prompt 和 Chain of Thought 的做法都是对于一个新任务,不再改变模型,而是给出一些例子,让模型通过这些例子学习新的任务。这种方法被称为 In Context Learning(ICL)。Finetune 为什么能够适应新的任务容易理解,他通过梯度下降使得模型参数发生了改变,那么在 ICL 中发生了什么变化呢?
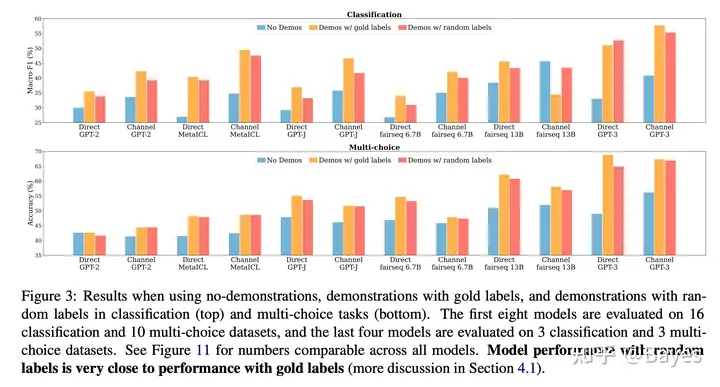
文章 Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?认为对于 ICL 最重要的因素并不是例子的正确性,而是示例的输入输出序列的分布。我粗浅的理解是,在 ICL 过程中模型并没有获取新的知识,即如何解决问题是模型本身具备的能力,而 context 只是给出了需要完成的到底是什么任务。下图做给出的是在不同的任务上使用正确答案(黄)和使用错误答案(红)的效果对比,可以看到效果没有非常明显的差异。而下图右给出的是使用错误格式的 context(紫)和正确格式错误答案(红)的差异,可见效果下降明显。
如何让模型更听话¶
无论是 Prompt 还是更复杂的 CoT,他们的思想都是给更服从预训练分布的输入,激发模型的能力。这些方法展现出了很好的效果,但是这是对于工程师来讲,对于一般用户来说这还是有点复杂。所以是不是有一种方法可以不再让人适应模型而是让模型适应人。这就是接下来要说的 Instruction-tuning 和 RLHF 想解决的问题。
Instruction-tuning¶
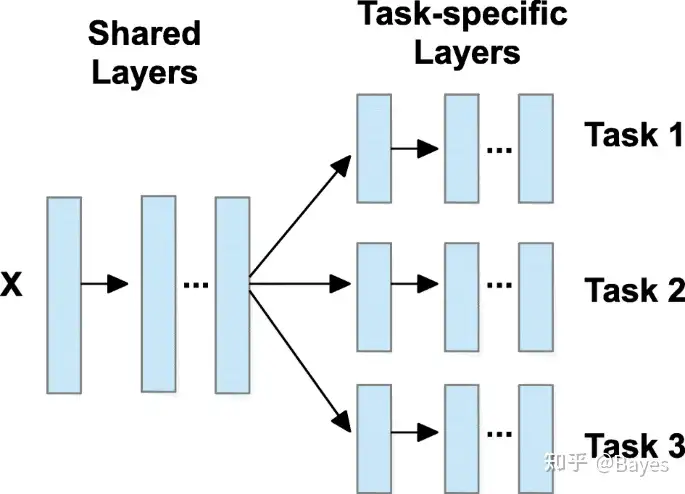
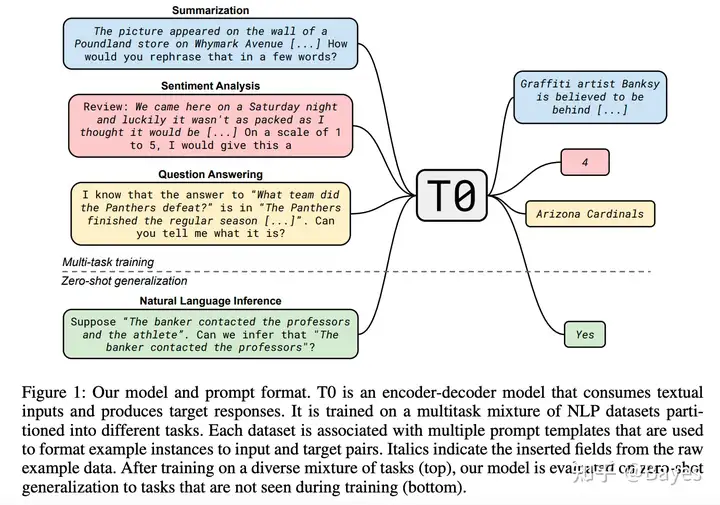
instruction-tuning 的主要方法很简单,即在预训练模型之后再使用大量下游任务的数据进行 Finetune。不过不同于一般多任务 Finetune 的方式,instruction-tuning 中将不同的任务都转换成了语言建模任务。下图左是一般的多任务训练方式,有些公用的层,最后有任务专属的层;下图右为论文 T0: MULTITASK PROMPTED TRAINING ENABLES ZERO-SHOT TASK GENERALIZATION 中提出的方法,将任务专属的模型参数转换为了任务专属的提示语,并且这些提示语也都是自然语言,通过这样的方法实现一个模型可以处理多种任务。
同期的 FLAN: FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS 也采用了类似的方法,下图是 FLAN 中总结的 Finetune/Prompt/Instruction 之间的差异。实际上这么比较也不是特别合理,因为我们可以看出下图的 ABC 三种方法要处理的任务存在一定差异。
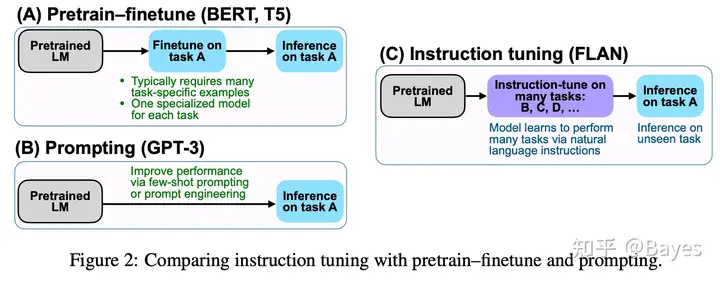
1.Pretrain-Finetune
这里 Finetune 也可以实现多任务训练,所以他是一种实现在某些特定任务上效果最好的方法。
2.Prompt
他比 Finetune 能处理的任务更多一些,除了训练过的特定任务还具备一定的处理未训练过任务的能力(实际也不一定的完全没见过,可能已经包含在预训练中了)。在 CoT 中也存在类似的方法,论文 Large Language Models are Zero-Shot Reasoners 提出了一个神奇的现象,在没有详细的思维链示例时可以在最后加一句 Let's think step by step,就可以显著提升模型的 zero-shot 能力。 在 few-shot 方面他和 Finetune 类似,只不过一个调的是模型参数,一个调的是输入参数,目标都是为了在特定任务上获得好的效果。虽然看似 Finetune 需要反向传播计算量大,但是找到一个好的 Prompt 也不是一个简单的方式,如果是离散的 Prompt(即一句话)看起来不需要方向传播,但是因为没有很好的优化方式(比如一般强化学习相比于直接反向传播训练会更不稳定收敛性也差一些)可能需要更多次的前向计算;而如果使用连续的 Prompt(即使用 Embedding 作为 Prompt)其实也需要反向传播。所以这个成本可能没有想的那么低。
3.Instruction-tuning
参考上图也可以看到,他的任务和上面两种并不相同。他想要处理的是一种新任务,实现的是能够处理未见过任务的能力,下图左为 FLAN 展示的结果,可以看出他展示的都是 zero-shot 的效果,即新任务上的效果。在 Challenging BIG-Bench tasks and whether chain-of-thought can solve them 中也比较了 instructGPT 和 Codex 的效果(instructGPT 基于 Codex)。可以看出在 Few-shot 场景上 Codex 取得了最好的效果。这一点在 InstructGPT 论文中也有提到。
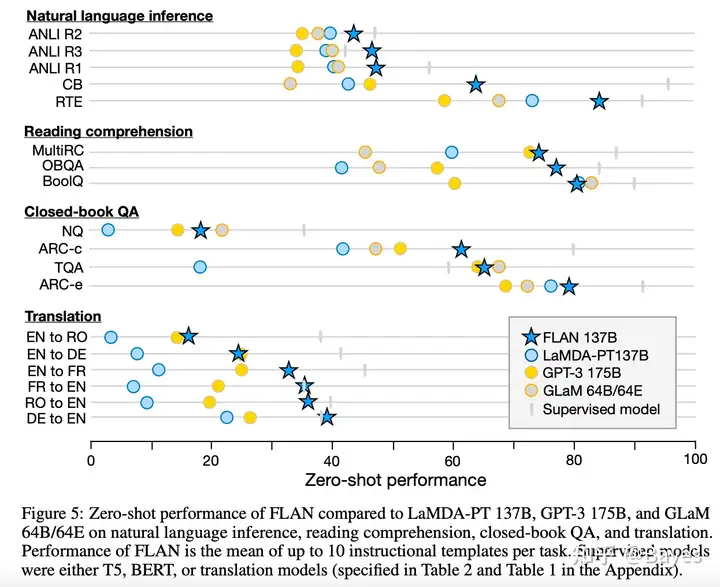
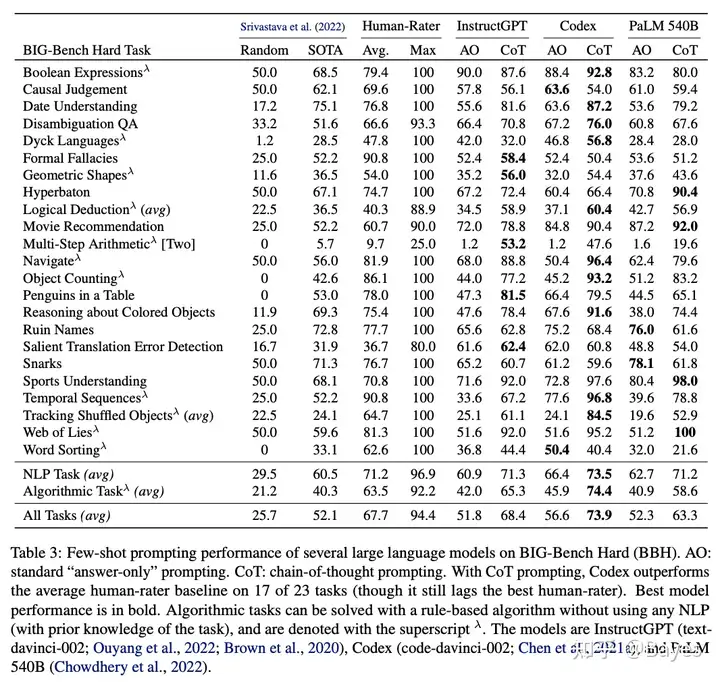
论文 Galactica: AI4Science 进行了一个很好的总结,这几种方法各有优劣。我认为至少现在还不存在某一个方法全方法超过其他方法。还是应当根据具体的场景来选择方案。比如明确要用的场景就是中英翻译那么 Prompt/CoT 还是更好的,如果是一个搜索引擎因为用户存在大量不同的需求那么 Instruction 会更好一些,而进行instruction-tuning的训练过程正是使用的Finetune。
FLAN-PaLM: Scaling Instruction-Finetuned Language Models AI2: COMPLEXITY-BASED PROMPTING FOR MULTI-STEP REASONING
RLHF¶
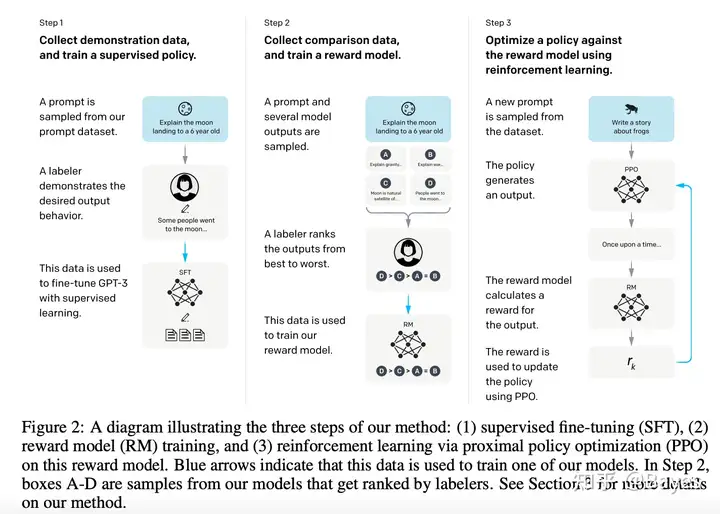
前面介绍的 Instruct-tuning 主要做法还是将一些已有的下游任务转换成自然语言 Prompt,但是这些认为抽象出的自然语言任务是有限的,并且每一个任务都进行了拆分,实际的任务可能是更复杂的。比如“帮我用法文简单概括一下 GPT-3 这篇文章”,这里就同时包含了翻译/摘要抽取任务。所以为了能够更好的让模型适应人 Instruct-GPT: Training language models to follow instructions with human feedback 提出可以使用更真实的输入分布来进行学习。
同时前面的方法还存在一个严重的问题,那就是目前已有的任务他们都包含一个标准答案。但是实际上大部分生成任务不一定有一个标准答案,而是很多答案都可行。为了解决这一点在 instruct-GPT 中提出我们不应当学习一个标准答案,而是应该学习出一个人类觉得最好最通顺的答案。说的很好,但是这个人类觉得最好是一个难以具体评估的标准。当我们面对一个难以显式编码的东西目前最好的解决方法就是使用 Deep Learning。因此文中提出使用另一个模型叫做 Reward Model 来判断一条答案是否符合人类预期。其实这也不是什么新方法,在 GAN 中就存在一个判别器来判断生成内容是不是真实的。
最后 GPT 的输出是离散的即一段文字,这个离散化导致 Reward Model 的梯度难以反向传播回生成模型上,为了解决这个问题论文提出可以使用强化学习方法来进行优化。实际上我认为这并不是必须的,因为解决这个的问题方法太多了比如重参数化等,所以这里我们就不再详细介绍。
我们可以看到 RLHF 虽然看起复杂但是他和一般的优化思路其实是一致的
- 更接近线上数据分布的训练数据
- 更接近最终目标的 Loss
- 一个可行的优化方法
实际上更早就有一些论文使用 RL 来优化语言任务,但是并没有这么轰动的效果。所以一个人的命运啊,当然要靠自我奋斗,但是也要考虑到历史的进程。到 LLM 时代才迎来真正的效果突变。 PPO: Proximal policy optimization algorithms Deep reinforcement learning from human preferences Fine-Tuning Language Models from Human Preferences Learning to summarize from human feedback Sparrow: Training an AI to communicate in a way that’s more helpful, correct, and harmless RL4LMs github
接下来还需要什么¶
上面我们就已经基本讲完了 ChatGPT 中所包含的技术,但是在最开始我们分析了一些搜索引擎所需要的东西目前还没有被 ChatGPT 很好的解决。接下来我们简单展望一下。
Model as Database¶
为什么模型就是数据库¶
首先就是我们提到的,ChatGPT 直接将知识编码在模型参数中,避免了一个显式的数据库,我们首先看一下为什么可以说模型就是一个数据库。
一样,实际就是在空间中画一条线,一侧是证样本,一侧是负样本。
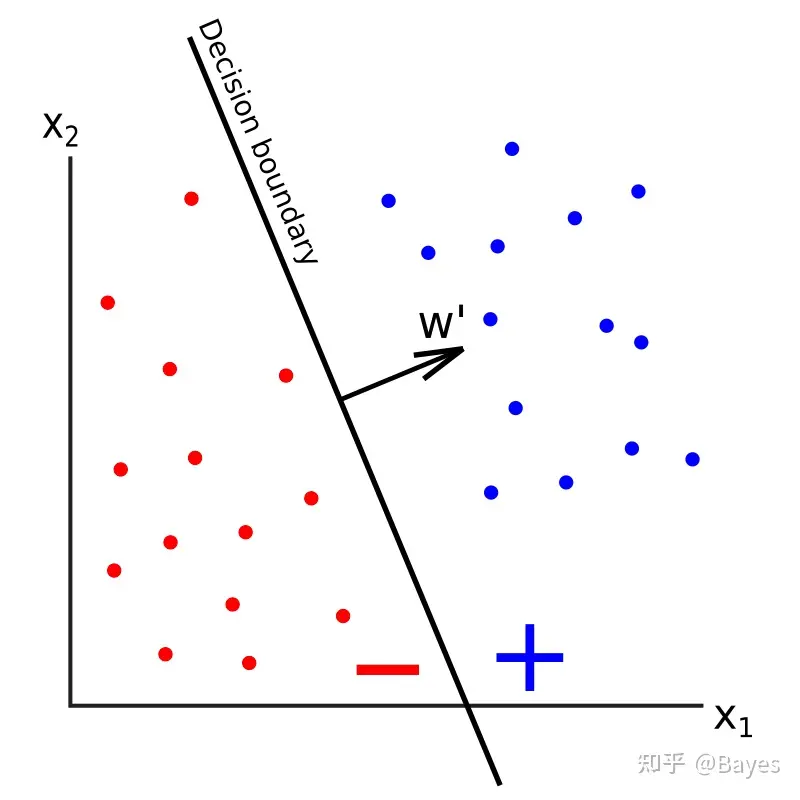

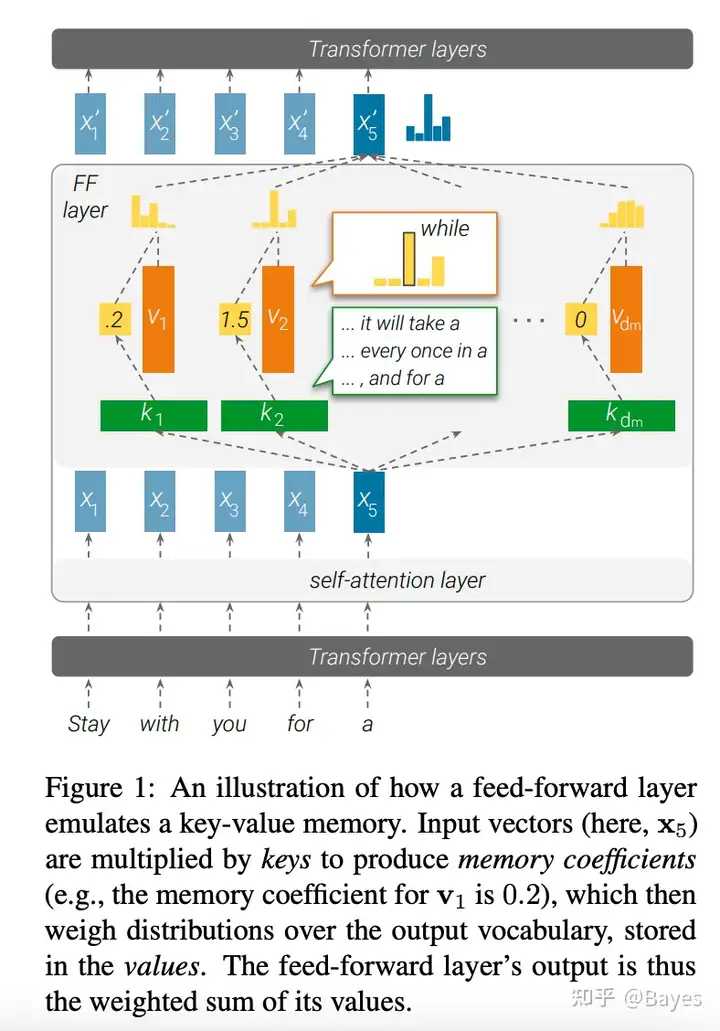
具体分析差不多,就是说 FFN 可以分解成对训练样本的加权。文章继续进行了一些实验,首先对 FFN 中第一个 dense 的每一行找一个最相似的前缀,然后发现这些前缀具有一定的特征。另外比较了第二个 dense 的输入,发现他们和句子的下一个词的词向量具有较高的相似性。通过这两点作者宣称 FFN 的两层分别实现了 key 和 value 的作用。
如何操作模型这个数据库¶
知道了模型可以当作数据库之后一个自然的问题就是,如何把在模型中实现常见的数据库操作,比如修改一条知识。做到这一点 ChatGPT 才真有可能完全取代搜索引擎。下面两篇论文讨论了这个问题,之后补充。 MASS-EDITING MEMORY IN A TRANSFORMER Locating and Editing Factual Associations in GPT
External Module¶
除了数据库这一部分,现代搜索引擎还引入了大量外部的工具,比如计算器。但是 ChatGPT 完全依赖模型来实现所有这些工具,这是不必要的,所以我们考虑一下如何在 ChatGPT 中也引入外部工具。
在 Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks 中提出了一个有趣的想法,既然目前 LLM 擅长自然语言都是在计算方面不太好,那我们知道一个很擅长计算的东西那就是各种编程语言,但是他们只能处理编写好的程序不能处理自然语言。那我们可以将两者结合起来,通过 LLM 将自然语言转换为机器语言,使用解释器执行机器语言,这样在一些需要计算的任务上可以取得较好的效果。下图左也能看出在一些计算任务上自然语言的缺陷。下图右可以看到文章通过上述方法在多个需要计算的任务上取得了显著的优势。

虽然 PoT 在计算任务上效果良好,但是通过这样的方式应当牺牲了很多自然语言任务上的效果。在 Galactica: AI4Science 中提出了一个可以部分缓解这个问题的方法。见下图右,通过一个特殊的 Token: [work]标志哪一部分应当由外部模块执行。同时文章提出了一个观点,即 CoT 也属于一种使用外部模块的方法,见下图左。在 CoT 中外部模块只起到了记忆的作用,而在 PoT 中外部模块除了记忆还可以运算,这么看来确实本文的方法应该是优于 CoT 的。
虽然使用 Galactica 部分缓解了这个问题,但是我认为和外部模块的交互只在最终输出后,这好像还是不够灵活,是否有一种方法能在模型中和外部模块交互感觉是一个值得研究的问题。最后说一句哲理的外部模块也可以是另一个 LLM。 Program of Thoughts github
ChatGPT时代应该做什么¶
在上文中我们讨论了如何实现一个ChatGPT,我们在这里思考一下它实现了哪些新的能力,以及实现它需要哪些条件。新能力创造了新需求
- 模型实现复杂推理,在科学领域需要强大的推理能力
- 模型实现知识存储,提供了一种数据存储检索的方法
- 模型实现域外泛化,对于不确定的输入有较好的效果,最直接的就是ChatGPT
而实现这些新需求则需要具备这些条件
- 算法,首先就是我们在上文中指出需要解决的算法问题,所以做算法还是需要的
- 数据,无论是预训练是否可以有更好的任务还是下游数据的处理选取都很重要
- 工程,我们上面提到GPT的计算量依然很大,无论是在训练还是推理都是一个难题可参考 训练ChatGPT需要什么-超大模型训练part1(机器学习系统)
- 硬件,ChatGPT实现了端到端的搜索,把原本的很多种计算转变为了统一的矩阵乘法,如果能够统一更多的计算那么现在矩阵"专用"处理器可以变成"通用"处理器
下面简单介绍一篇在科学领域应用GPT的文章Galactica: AI4Science。文章方法并不复杂,但是提到的一些想法很有深度。文章首先将科学领域的一些表示转变为自然语言,对不同类型使用不同的标记。

其次引入了一个[work]标记,是的部分计算可以被卸载到外部模块,不过最终并没有使用外部模块。那这部分我理解就相当于CoT。最后文章在预训练阶段也引入了更多Prompt,以使得下游再使用Prompt时能取的更好的效果。
方法虽然不复杂但是已经取得了明显的提升,其中还是有很多可以改善的地方,比如数学符号如何输入/如何对齐自然语言和数学符号等。
推荐资料¶
最后推荐两篇文章,第一篇文章有很多作者的思考并且提到了很多文章可供参考,第二篇文章对于模型能力的起源有深入分析,值得学习一下 通向 AGI 之路:大型语言模型(LLM)技术精要 拆解追溯 GPT-3.5 各项能力的起源
(来源:知乎https://zhuanlan.zhihu.com/p/604690133 侵删)