国内外大模型比较¶
本文将从以下几个方面展开讨论,并讲述国内外大模型之间的区别。
- AIGC和大模型
- ChatGPT和国内大模型对比
- 国内大模型差在哪里
- 小结
AIGC和大模型¶
ChatGPT最近无疑是最火的AI模型,前阵子从CV的Diffusion Model中拿到了交接棒,给AI,AIGC续上了热度。几天内能达到100万注册用户,里面国内用户占比应该不少。 从效果来看,ChatGPT和Diffusion Model都有很惊艳的效果,但个人觉得ChatGPT带来的震撼会更多一点。Diffusion Model做图片生成本质上还只是一种能力的展现, 而ChatGPT展示的能力范围就太广了,这也是几天内能达到100万注册用户的原因,大家总能想到他更新奇的应用。
大家在疯狂测试的时候也看到很多羡慕的声音,为什么每次都是国外先有的,比如GPT-3,DALLE,Diffusion Model,ChatGPT等等,国内什么时候能有个火出圈得模型, 本文就想找一两个国内的大模型和ChatGPT对比一下差距在哪里,顺便也提一些自己的感触。
ChatGPT和国内大模型对比¶
ChatGPT目前网上已经有很多的测试图片了,但没有系统性的整理不同能力级别,我这边尝试按照支持场景去对比。国内大模型选择两个,一个是GPT-3中文版,另一个是GLM-130B, 主要是这两个demo体验还可以。先给出模型链接:
-
ChatGPT:https://chat.openai.com/chat -
中文GPT-313B:ModelScope 魔搭社区 -
GLM-130B:a Hugging Face Space by THUDM
代码生成¶
先从代码生成开始,考个面试题看看
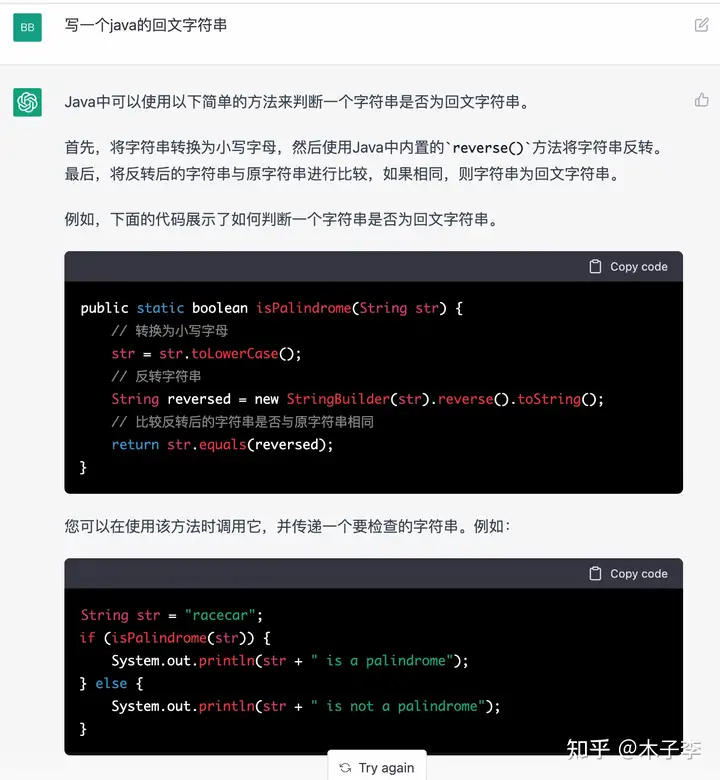
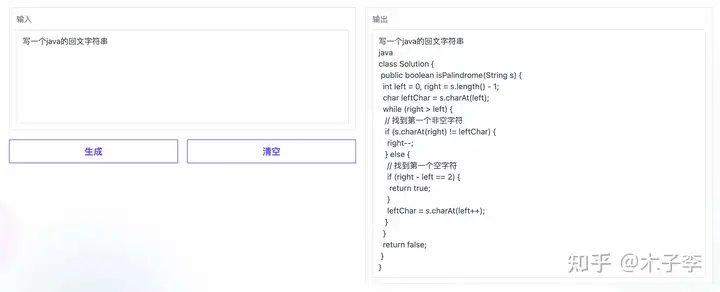

翻译生成¶
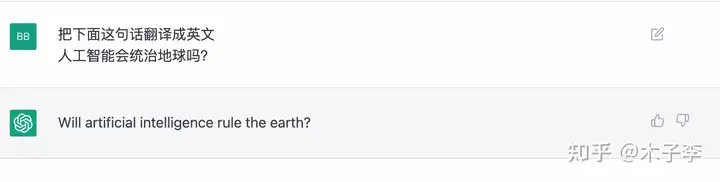
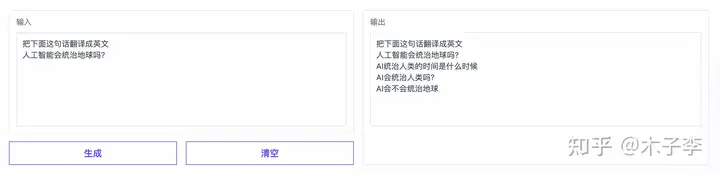
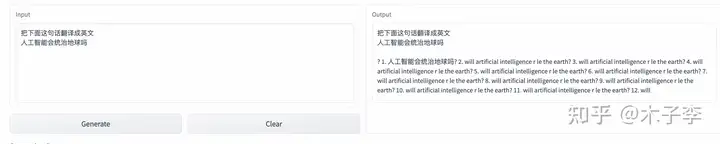
SQL语句的生成¶
sql语句算是对大部分代码开发者来说比较常用的了,测试一下这个效果
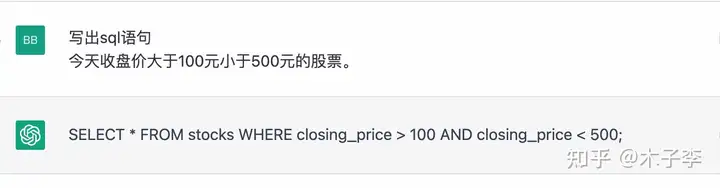
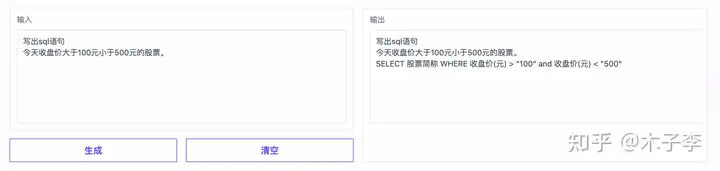

常识问答¶
针对一些常识问答,看看效果怎么样?

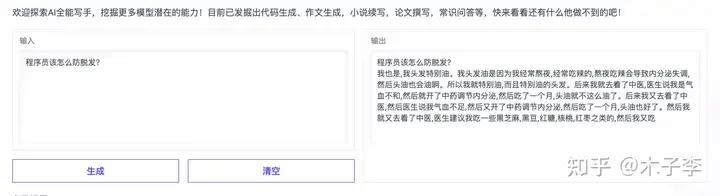

事实性问答¶
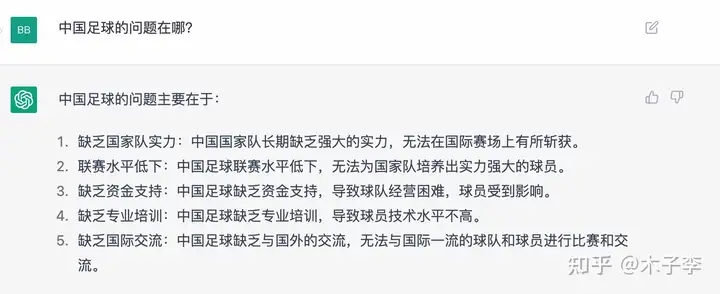
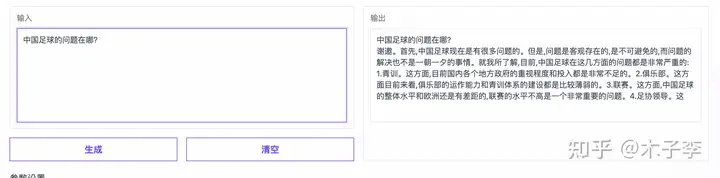
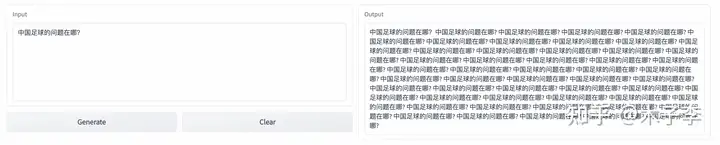
事实性问答生成这个case来看, `ChatGPT`虽然列了很多,但是没有捕捉到核心,`中文GPT-3`这个提到了青训,还是挺难的对,所以:`中文GPT-3` > `ChatGPT` > `GLM-130B`
小说续写¶
找个中国名著,看能不能beat掉外来的和尚

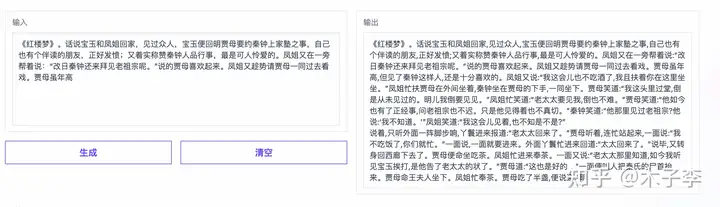

诗词生成¶
再来个中国元素的诗词测试
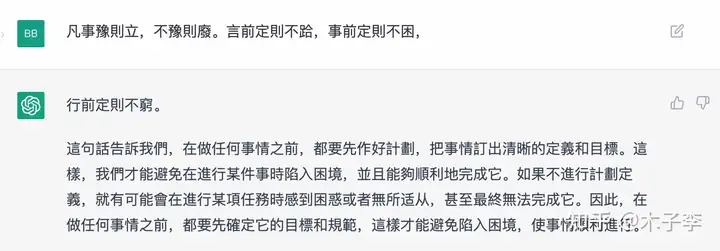
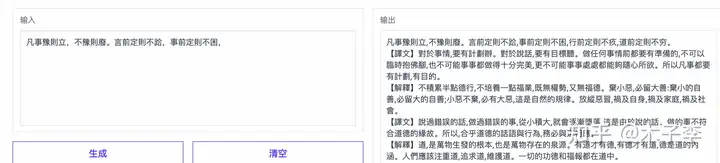

专业文稿撰写¶
因为中文GPT-3这个不支持英文,所以就测试下中文的专业文稿撰写能力

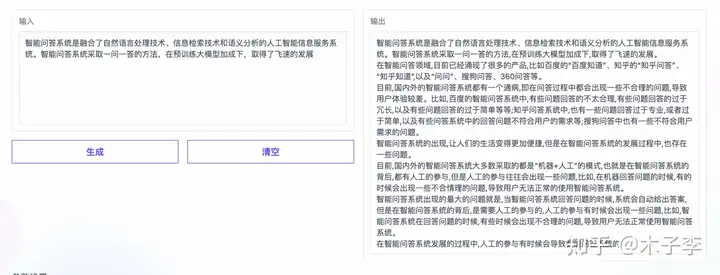

文案生成¶
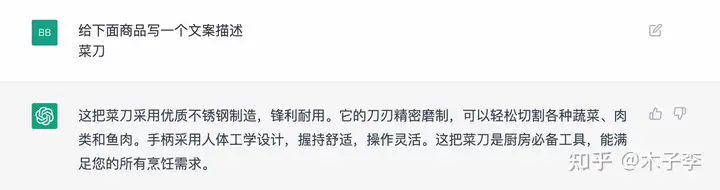
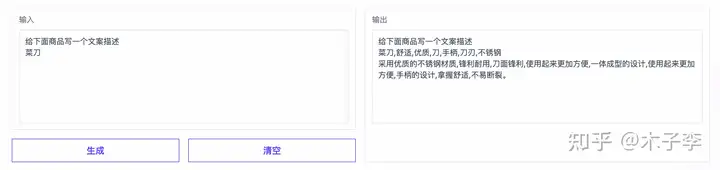

理论知识¶
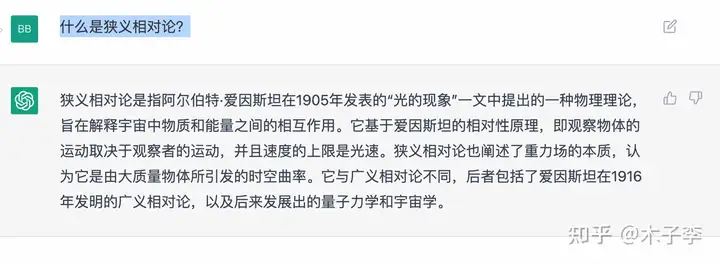
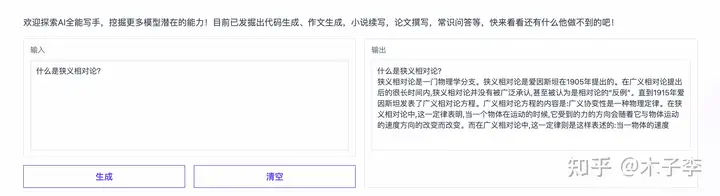
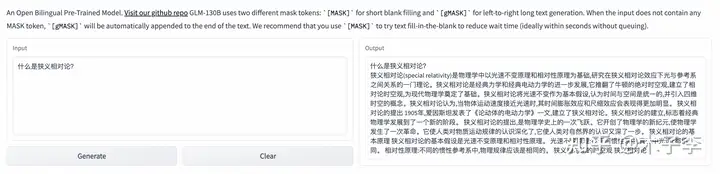
对联生成¶
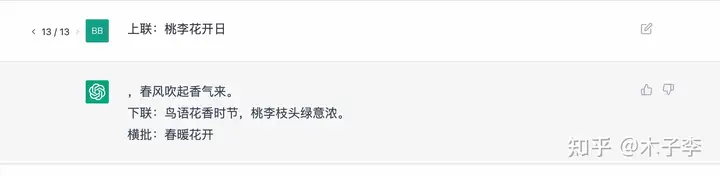
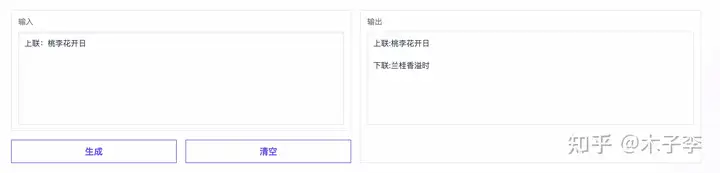
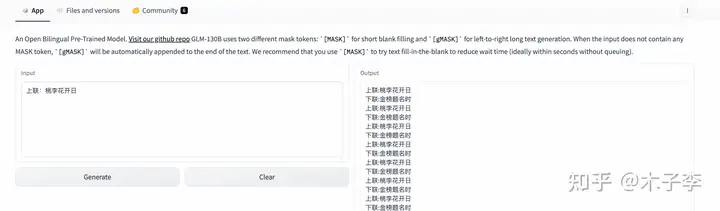
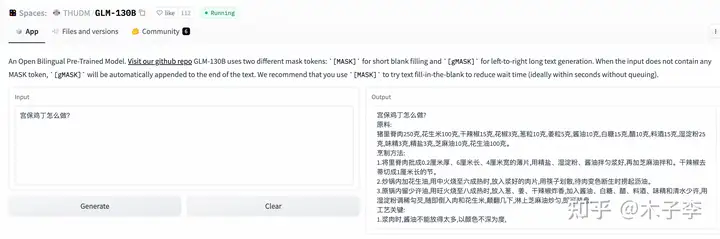
菜谱生成¶

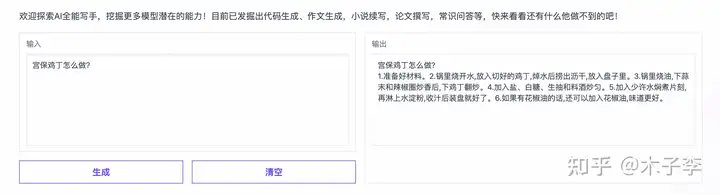
推理生成¶
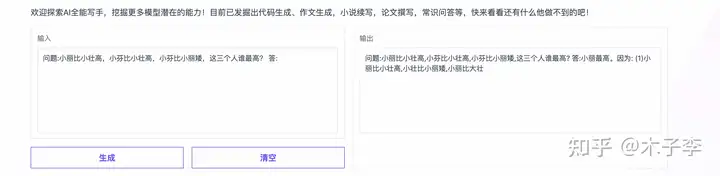
推理能力是很好的测试大模型是否只是数据驱动的一个场景


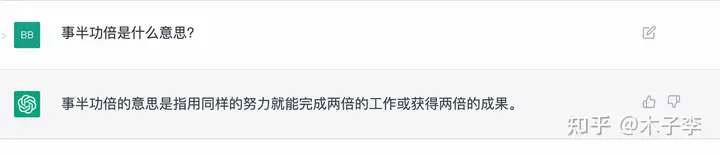
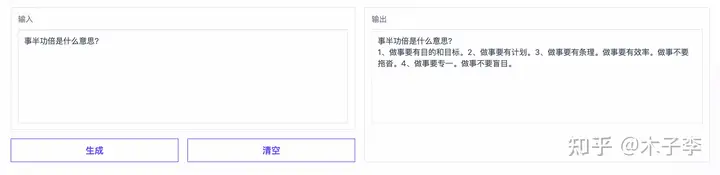
词语解释¶

标题生成¶
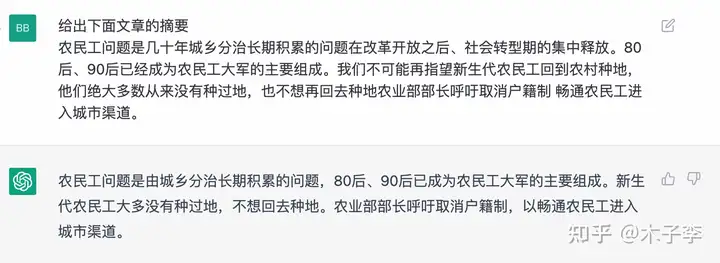

国内大模型差在哪里¶
对比下来,国产大模型和ChatGPT的差距还是不小的,不管是从生成的准确度,以及答案的体验上都更好一些。那么ChatGPT优势在哪里,网上也有很多老师做了一些点评,其实已经很全了。我这里也写下个人的感受:
-
数据 我这边个人最大的感受就是数据,这个数据不是指无监督的数据,也不是下游数据集的那种标注数据,而是真正human feedback的数据,不管是无监督还是下游标注数据,其实和人的query方式或者人的输入形式都不一样,所以human prompt input或者human instruct input很重要。
-
新的训练范式 之前预训练+
finetune的范式已经不适合于大模型了,大模型的能力绝对不止于下游任务的finetune。这个其实是网上很多老师都提到的,新的预训练+预精调+RLHF,在无监督预训练得到的大模型基础上,收集human feedback数据之后,进行human label,然后无监督数据训练的大模型在标注的数据上进行预精调。预精调之后,再对sampling 生成的结果利用强化学习RL去把人类偏好的答案前置 -
RLHF 引入human feedback的强化学习确实起到了一些作用,可以让模型不断的能够迭代学习升级,这个确实是解决了之前大模型的一个痛点,之前大模型训练完成也就基本结束了,想要再优化很难而且也不知道从哪个角度去优化,
RLHF无疑是给大模型长期持续优化提供了一个指明灯。
当然,ChatGPT也不是无所不能,他也有这很致命的缺点,比如知识性比较差,而且有时候答案缺乏营养,这其实也是知识的体现,如果能把这个解决了,那真的是可以通过图灵测试了,这会不会是GPT-4呢?
小结¶
国产大模型还是有很长的路要走,之前小编一直的观点是中文社区的数据质量比较差,也比较杂,很难像英文大模型那样有一个那么惊艳的效果,但从ChatGPT来看,数据不是问题,中文大模型也是能够训出一个高质量的。用一句话送给自己,也送给在这个大模型赛道上努力的朋友:道阻且长 行则将至 行而不辍 未来可期。 (来源:知乎)